Comanda Linux `uniq` analizează fișierele text în căutarea rândurilor unice sau a celor care apar în mod repetat. Acest ghid explorează flexibilitatea și capacitățile acestei unelte, demonstrând cum să o folosești eficient.
Identificarea corectă a rândurilor de text în Linux
Comanda `uniq` este rapidă, versatilă și excelentă în domeniul său. Cu toate acestea, ca multe comenzi Linux, are particularitățile sale, care devin ușor de gestionat odată ce le cunoști. Fără o minimă pregătire, rezultatele ar putea fi neașteptate. Vom detalia aceste aspecte pe parcurs.
Comanda `uniq` este ideală pentru cei care preferă un instrument dedicat, concentrat pe o singură funcție. De asemenea, se integrează excelent în structurile de tip pipeline, jucând un rol important în lanțul de procesare a comenzilor. Unul dintre cei mai frecvenți parteneri ai săi este comanda `sort`, deoarece `uniq` necesită ca datele de intrare să fie deja ordonate.
Să vedem cum funcționează!
Utilizarea comenzii `uniq` fără opțiuni
Avem un fișier text cu versurile cântecului lui Robert Johnson, „I Believe I’ll Dust My Broom”. Să analizăm comportamentul comenzii `uniq` cu acest fișier.
Vom introduce următoarea comandă pentru a transmite rezultatul către `less`:
uniq dust-my-broom.txt | less
Rezultatul afișează întregul cântec, inclusiv rândurile duplicate:
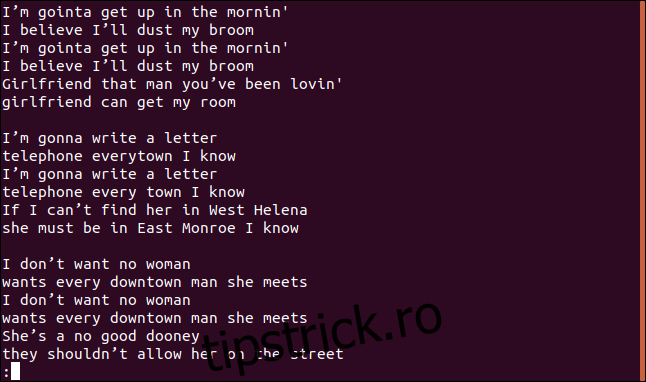
Nu pare a afișa doar rândurile unice, nici pe cele duplicate.
Corect, aceasta este prima particularitate. Dacă rulezi `uniq` fără opțiuni, se comportă ca și cum ai folosi opțiunea `-u` (linii unice). Aceasta indică comenzii să afișeze doar rândurile care apar o singură dată în fișier. Motivul pentru care vedem și rânduri duplicate este că `uniq` le consideră duplicate doar dacă sunt adiacente. Aici intervine comanda `sort`.
Când ordonăm fișierul, rândurile identice sunt grupate, permițând comenzii `uniq` să le proceseze corect ca duplicate. Vom sorta fișierul, vom transmite rezultatul către `uniq`, apoi rezultatul final către `less`.
Pentru a realiza acest lucru, introducem următoarea comandă:
sort dust-my-broom.txt | uniq | less

În `less` este afișată o listă de rânduri unice, ordonate alfabetic.
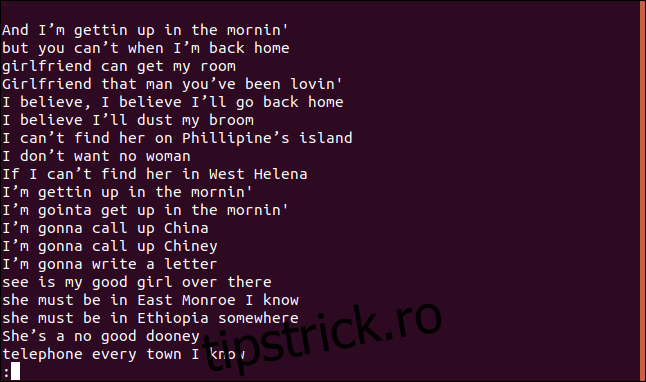
Rândul „Cred că îmi voi face mătura de praf” apare în mod cert de mai multe ori în cântec, de fapt, se repetă de două ori în primele patru rânduri.
De ce apare într-o listă de rânduri unice? Deoarece prima apariție a unui rând în fișier este considerată unică, doar aparițiile ulterioare sunt considerate duplicate. Practic, este afișată prima apariție a fiecărui rând unic.
Să folosim din nou comanda `sort` și să redirecționăm rezultatul într-un fișier nou. Astfel, nu mai trebuie să sortăm de fiecare dată când folosim comanda.
Introducem următoarea comandă:
sort dust-my-broom.txt > sorted.txt
 =”” sorted.txt=”” într-o=”” fereastră=”” de=”” terminal.” width=”646″ height=”57″ onload=”pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);” onerror=”this.onerror=null;pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);”>
=”” sorted.txt=”” într-o=”” fereastră=”” de=”” terminal.” width=”646″ height=”57″ onload=”pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);” onerror=”this.onerror=null;pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);”>
Acum avem un fișier deja sortat cu care putem lucra.
Numărarea duplicatelor
Se poate folosi opțiunea `-c` (numără) pentru a afișa de câte ori apare fiecare rând într-un fișier.
Introduceți următoarea comandă:
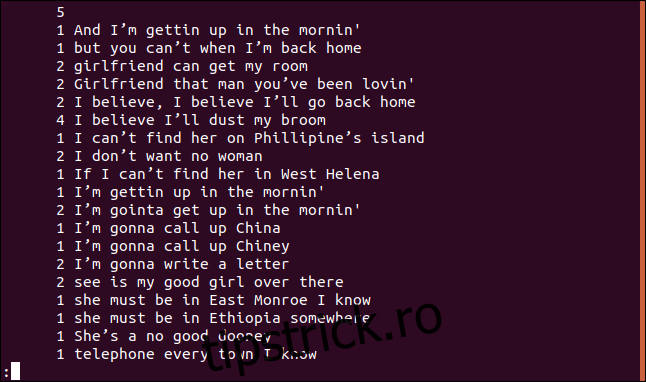
uniq -c sorted.txt | less

Fiecare rând începe cu numărul de apariții în fișier. Observăm că prima linie este goală, indicând existența a cinci rânduri goale în fișier.
Pentru a sorta rezultatul în ordine numerică, putem transmite ieșirea comenzii `uniq` către `sort`. Vom folosi opțiunile `-r` (invers) și `-n` (sortare numerică) și vom trimite rezultatul către `less`.
Introducem următoarea comandă:
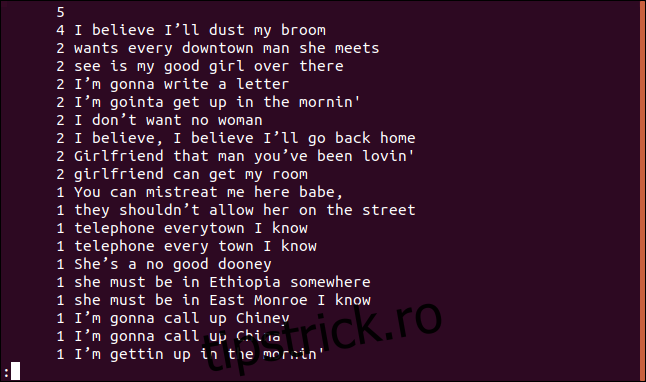
uniq -c sorted.txt | sort -rn | less

Acum, lista este sortată în ordine descrescătoare, conform frecvenței de apariție a fiecărui rând.
Afișarea exclusivă a rândurilor duplicate
Dacă dorim să vedem doar rândurile care se repetă într-un fișier, putem folosi opțiunea `-d` (repetate). Indiferent de câte ori apare un rând duplicat, acesta va fi listat o singură dată.
Pentru a folosi această opțiune, introducem următoarea comandă:
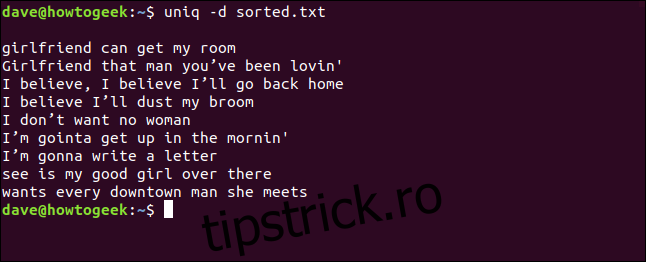
uniq -d sorted.txt

Sunt listate rândurile duplicate. Observați linia goală de la început, indicând faptul că fișierul conține rânduri goale duplicate. Nu este un spațiu adăugat de `uniq` pentru estetica listei.
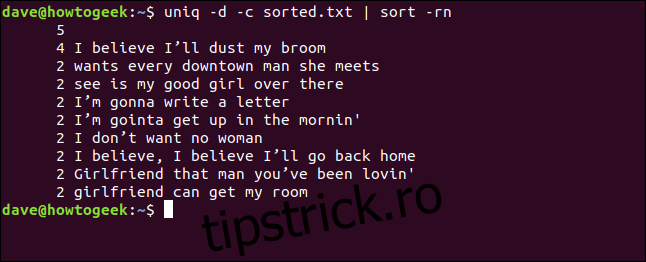
Putem combina opțiunile `-d` (repetate) și `-c` (numără) și să transmitem rezultatul prin `sort`. Vom obține o listă sortată a rândurilor care apar de cel puțin două ori.
Introduceți următoarea comandă pentru a folosi această opțiune:
uniq -d -c sorted.txt | sort -rn
Listarea tuturor liniilor duplicate
Dacă dorim o listă a fiecărui rând duplicat, incluzând câte o intrare pentru fiecare apariție, putem folosi opțiunea `-D` (toate liniile duplicate).
Pentru a utiliza această opțiune, introducem următoarea comandă:
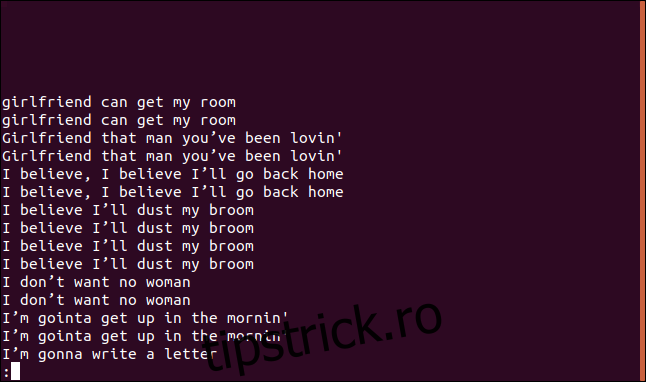
uniq -D sorted.txt | less

Lista conține o intrare pentru fiecare rând duplicat.
Dacă folosim opțiunea `–group`, fiecare grup de rânduri duplicate va fi tipărit cu o linie goală înainte (adăugați), după (adăugați) sau ambele (ambele).
Vom folosi modificatorul `append`, astfel că introducem următoarea comandă:
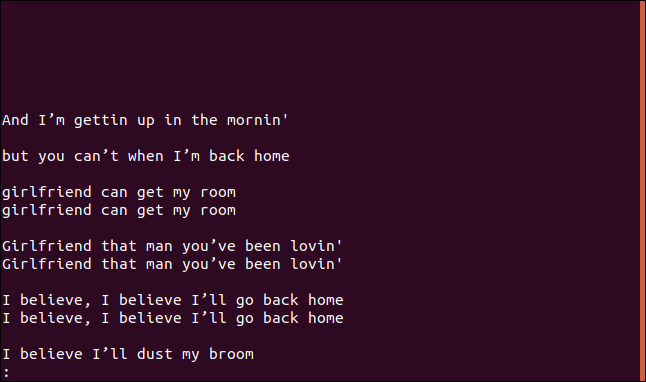
uniq --group=append sorted.txt | less

Grupurile sunt separate prin linii goale pentru o mai bună lizibilitate.
Verificarea unui număr limitat de caractere
Implicit, comanda `uniq` verifică întreaga lungime a fiecărui rând. Pentru a limita verificările la un număr specific de caractere, se poate folosi opțiunea `-w` (verifică caractere).
În acest exemplu, vom repeta ultima comandă, limitând comparațiile la primele trei caractere. Pentru a face acest lucru, introducem următoarea comandă:
uniq -w 3 --group=append sorted.txt | less

Rezultatele și grupările obținute sunt diferite.
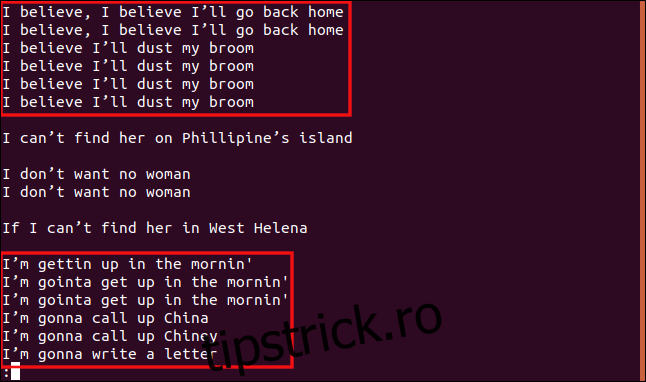
Toate liniile care încep cu „I b” sunt grupate, deoarece acele porțiuni ale liniilor sunt identice, fiind considerate duplicate.
De asemenea, toate liniile care încep cu „Sunt” sunt tratate ca duplicate, chiar dacă restul textului diferă.
Ignorarea unui număr de caractere
În anumite situații, poate fi util să omitem un număr de caractere de la începutul fiecărui rând, cum ar fi atunci când rândurile dintr-un fișier sunt numerotate. Sau, să presupunem că avem nevoie ca `uniq` să ignore un marcaj temporal și să înceapă verificarea de la al șaselea caracter.
Mai jos este o versiune a fișierului nostru sortat, cu linii numerotate.
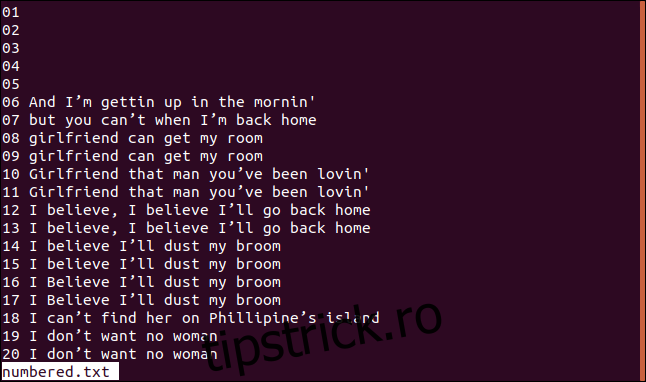
Dacă vrem ca `uniq` să înceapă comparațiile de la al treilea caracter, putem folosi opțiunea `-s` (salt caractere) tastând următoarea comandă:
uniq -s 3 -d -c numbered.txt
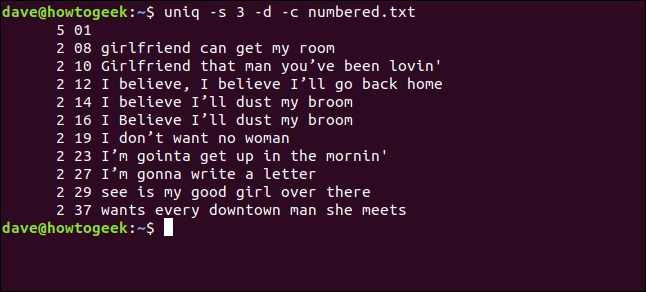
Rândurile sunt detectate ca duplicate și numărate corect. Observăm că numerele de rând afișate sunt cele de la prima apariție a fiecărui duplicat.
De asemenea, se pot omite câmpuri (o serie de caractere și spații albe), în loc de caractere individuale. Vom folosi opțiunea `-f` (câmpuri) pentru a indica comenzii `uniq` ce câmpuri să ignore.
Introducem următoarea comandă pentru a indica comenzii `uniq` să ignore primul câmp:
uniq -f 1 -d -c numbered.txt
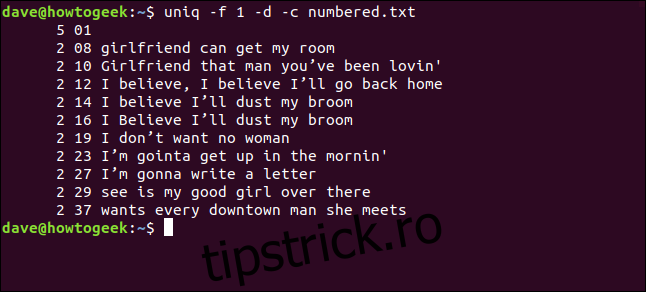
Obținem aceleași rezultate ca atunci când am indicat comenzii `uniq` să omită trei caractere de la începutul fiecărui rând.
Ignorarea majusculelor și minusculelor
Implicit, comanda `uniq` face distincție între majuscule și minuscule. Dacă aceeași literă apare cu majusculă și minusculă, comanda `uniq` consideră că rândurile sunt diferite.
De exemplu, verificăm rezultatul următoarei comenzi:
uniq -d -c sorted.txt | sort -rn
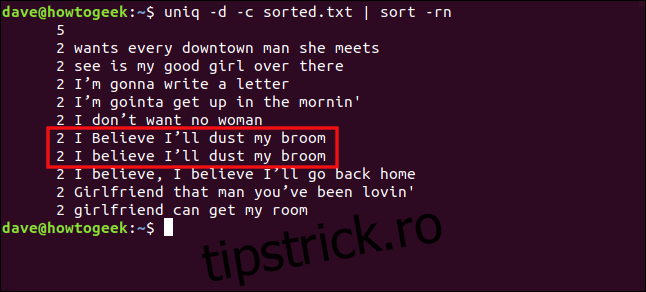
Rândurile „Cred că îmi voi șterge mătura” și „cred că îmi voi șterge mătura” nu sunt tratate ca duplicate, din cauza diferenței de majusculă de pe „C” în „Cred”.
Dacă includem opțiunea `-i` (ignoră majusculele), totuși, aceste rânduri vor fi tratate ca duplicate. Introducem următoarea comandă:
uniq -d -c -i sorted.txt | sort -rn
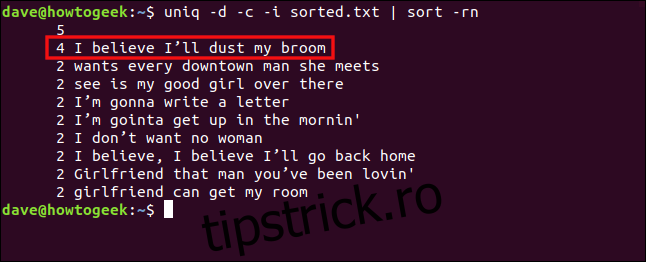
Rândurile sunt acum tratate ca duplicate și grupate.
Linux oferă o multitudine de utilitare specializate. Ca multe dintre acestea, `uniq` nu este un instrument pe care îl folosim zilnic.
O mare parte a competenței în Linux constă în a ne aminti ce instrument ne poate rezolva problema actuală și unde îl putem găsi. Prin practică, veți deveni tot mai pricepuți.
Sau, puteți oricând să căutați pe How-To Geek – probabil avem un articol despre asta.