
Ei bine, statisticile de la Forbes afirmă că până la 90% dintre organizațiile mondiale folosesc analiza Big Data pentru a-și crea rapoartele de investiții.
Odată cu creșterea popularității Big Data, există, în consecință, o creștere a oportunităților de angajare Hadoop mai mult decât înainte.
Prin urmare, pentru a vă ajuta să obțineți acel rol de expert Hadoop, puteți folosi aceste întrebări și răspunsuri la interviu pe care le-am adunat pentru dvs. în acest articol pentru a vă ajuta să treceți la interviu.
Poate că cunoașterea faptelor precum intervalul de salariu care fac ca rolurile Hadoop și Big Data să fie profitabile te va motiva să promovezi acel interviu, nu? 🤔
- Potrivit indeed.com, un dezvoltator Big Data Hadoop din SUA câștigă un salariu mediu de 144.000 USD.
- Potrivit itjobswatch.co.uk, salariul mediu al unui dezvoltator Big Data Hadoop este de 66.750 GBP.
- În India, sursa indeed.com afirmă că ar câștiga un salariu mediu de 16.00.000 INR.
Lucrativ, nu crezi? Acum, haideți să aflăm despre Hadoop.
Cuprins
Ce este Hadoop?
Hadoop este un cadru popular scris în Java care utilizează modele de programare pentru a procesa, stoca și analiza seturi mari de date.
În mod implicit, designul său permite extinderea de la un singur server la mai multe mașini care oferă calcul și stocare local. În plus, capacitatea sa de a detecta și gestiona defecțiunile stratului de aplicație, care au ca rezultat servicii foarte disponibile, face Hadoop destul de fiabil.
Să trecem direct la întrebările frecvent adresate la interviu Hadoop și la răspunsurile corecte ale acestora.
Întrebări și răspunsuri la interviu de la Hadoop
Ce este unitatea de stocare în Hadoop?
Răspuns: Unitatea de stocare a lui Hadoop se numește Hadoop Distributed File System (HDFS).
Cum este stocarea atașată la rețea diferită de sistemul de fișiere distribuit Hadoop?
Răspuns: HDFS, care este stocarea principală a Hadoop, este un sistem de fișiere distribuit care stochează fișiere masive folosind hardware-ul de bază. Pe de altă parte, NAS este un server de stocare a datelor de computer la nivel de fișier care oferă acces la date grupurilor eterogene de clienți.
În timp ce stocarea datelor în NAS este pe hardware dedicat, HDFS distribuie blocurile de date pe toate mașinile din clusterul Hadoop.
NAS utilizează dispozitive de stocare de ultimă generație, care este destul de costisitoare, în timp ce hardware-ul de bază utilizat în HDFS este rentabil.
NAS stochează separat datele din calcule, ceea ce îl face inadecvat pentru MapReduce. Dimpotrivă, designul HDFS îi permite să lucreze cu cadrul MapReduce. Calculele se deplasează către datele din cadrul MapReduce în loc de datele către calcule.
Explicați MapReduce în Hadoop și Shuffling
Răspuns: MapReduce se referă la două sarcini distincte pe care programele Hadoop le efectuează pentru a permite scalabilitate mare pe sute până la mii de servere dintr-un cluster Hadoop. Schimbarea, pe de altă parte, transferă rezultatul hărții de la Mappers la Reducerul necesar din MapReduce.
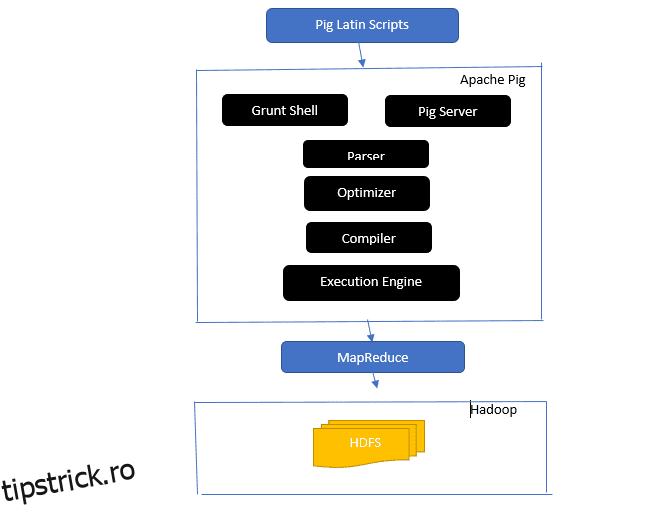
Oferă o privire asupra arhitecturii Apache Pig
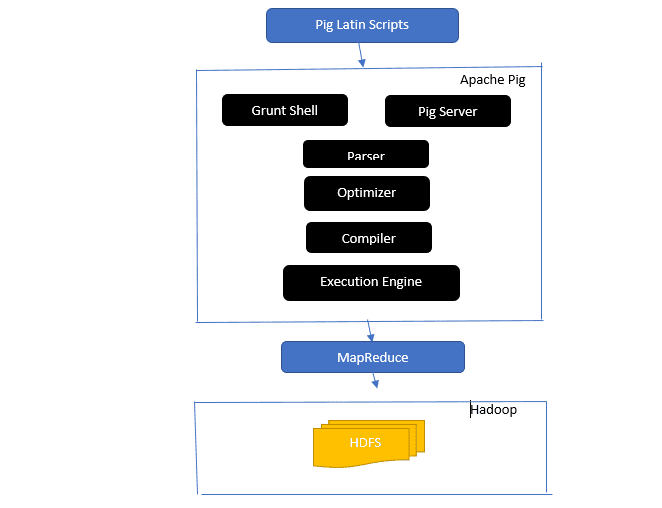 Arhitectura Apache Pig
Arhitectura Apache Pig
Răspuns: Arhitectura Apache Pig are un interpret Pig Latin care procesează și analizează seturi mari de date folosind scripturi Pig Latin.
Apache pig constă, de asemenea, din seturi de seturi de date pe care sunt efectuate operațiuni de date precum alăturarea, încărcarea, filtrarea, sortarea și gruparea.
Limba Pig Latin folosește mecanisme de execuție precum shell-uri Grant, UDF-uri și încorporate pentru scrierea scripturilor Pig care îndeplinesc sarcinile necesare.
Pig ușurează munca programatorilor prin conversia acestor scripturi scrise în seria de joburi Map-Reduce.
Componentele arhitecturii Apache Pig includ:
- Parser – Se ocupă de Scripturile Pig verificând sintaxa scriptului și efectuând verificarea tipului. Ieșirea parserului reprezintă declarațiile și operatorii logici ai lui Pig Latin și se numește DAG (graf aciclic direcționat).
- Optimizer – Optimizatorul implementează optimizări logice, cum ar fi proiecția și pushdown-ul pe DAG.
- Compilator – Compilează planul logic optimizat din optimizator într-o serie de joburi MapReduce.
- Motor de execuție – Aici are loc execuția finală a joburilor MapReduce în rezultatul dorit.
- Mod de execuție – Modurile de execuție în Apache pig includ în principal local și Map Reduce.
Răspuns: Serviciul Metastore din Local Metastore rulează în același JVM ca Hive, dar se conectează la o bază de date care rulează într-un proces separat pe aceeași mașină sau pe o mașină de la distanță. Pe de altă parte, Metastore din Remote Metastore rulează în JVM-ul său separat de JVM-ul serviciului Hive.
Care sunt cele cinci V-uri ale Big Data?
Răspuns: Aceste cinci V reprezintă principalele caracteristici ale Big Data. Ei includ:
- Valoare: Big data caută să ofere beneficii semnificative din randamentul ridicat al investiției (ROI) unei organizații care utilizează date mari în operațiunile sale de date. Big Data aduc această valoare din descoperirea și recunoașterea modelelor sale, rezultând, printre alte beneficii, relații mai puternice cu clienții și operațiuni mai eficiente.
- Varietate: Aceasta reprezintă eterogenitatea tipului de tipuri de date colectate. Diferitele formate includ CSV, videoclipuri, audio etc.
- Volumul: Acesta definește cantitatea și dimensiunea semnificativă a datelor gestionate și analizate de o organizație. Aceste date descriu o creștere exponențială.
- Viteza: aceasta este rata de viteză exponențială pentru creșterea datelor.
- Veracitatea: Verabilitatea se referă la cât de „incerte” sau „inexacte” sunt disponibile datele din cauza faptului că datele sunt incomplete sau inconsecvente.
Explicați diferitele tipuri de date de porc latin.
Răspuns: Tipurile de date din Pig Latin includ tipuri de date atomice și tipuri de date complexe.
Tipurile de date Atomic sunt tipurile de date de bază utilizate în orice altă limbă. Acestea includ următoarele:
- Int – Acest tip de date definește un întreg semnat pe 32 de biți. Exemplu: 13
- Long – Long definește un număr întreg de 64 de biți. Exemplu: 10L
- Float – Definește o virgulă mobilă de 32 de biți semnată. Exemplu: 2,5F
- Dublu – Definește o virgulă mobilă de 64 de biți semnată. Exemplu: 23.4
- Boolean – Definește o valoare booleană. Include: adevărat/fals
- Datetime – Definește o valoare dată-oră. Exemplu: 1980-01-01T00:00.00.000+00:00
Tipurile de date complexe includ:
- Hartă-Hartă se referă la un set de perechi cheie-valoare. Exemplu: [‘color’#’yellow’, ‘number’#3]
- Geantă – Este o colecție de un set de tupluri și folosește simbolul „{}”. Exemplu: {(Henry, 32), (Kiti, 47)}
- Tuplu – Un tuplu definește un set ordonat de câmpuri. Exemplu: (Vârsta, 33)
Ce sunt Apache Oozie și Apache ZooKeeper?
Răspuns: Apache Oozie este un planificator Hadoop responsabil de planificarea și legarea lucrărilor Hadoop împreună ca o singură lucrare logică.
Apache Zookeeper, pe de altă parte, se coordonează cu diverse servicii într-un mediu distribuit. Economisește timp dezvoltatorilor prin simpla expunere a serviciilor simple precum sincronizarea, gruparea, întreținerea configurației și denumirea. Apache Zookeeper oferă, de asemenea, asistență disponibilă pentru coadă și alegerea liderului.
Care este rolul Combinerului, RecordReaderului și Partitionerului într-o operație MapReduce?
Răspuns: Combinatorul acționează ca un mini reductor. Primește și lucrează asupra datelor de la sarcinile de hartă și apoi trece rezultatul datelor în faza de reducere.
RecordHeader comunică cu InputSplit și convertește datele în perechi cheie-valoare pentru ca mapper să le citească corespunzător.
Partiționerul este responsabil pentru a decide numărul de sarcini reduse necesare pentru a rezuma datele și pentru a confirma modul în care ieșirile combinatorului sunt trimise la reductor. Partitioner-ul controlează, de asemenea, partiţionarea cheilor a ieşirilor intermediare ale hărţii.
Menționați diferite distribuții specifice furnizorului de Hadoop.
Răspuns: Diferiții furnizori care extind capabilitățile Hadoop includ:
- Platforma IBM Open.
- Cloudera CDH Hadoop Distribution
- Distribuție MapR Hadoop
- Amazon Elastic MapReduce
- Platforma de date Hortonworks (HDP)
- Pivotal Big Data Suite
- Datastax Enterprise Analytics
- HDInsight de la Microsoft Azure – Distribuție Hadoop bazată pe cloud.
De ce este HDFS tolerant la erori?
Răspuns: HDFS reproduce datele pe diferite noduri de date, făcându-le tolerante la erori. Stocarea datelor în diferite noduri permite preluarea de la alte noduri atunci când un mod se blochează.
Faceți diferența între o federație și disponibilitate ridicată.
Răspuns: HDFS Federation oferă toleranță la erori care permite fluxul continuu de date într-un nod atunci când se blochează altul. Pe de altă parte, Disponibilitatea ridicată va necesita două mașini separate care configurează NameNode activ și NameNode secundar pe prima și a doua mașină separat.
Federația poate avea un număr nelimitat de NameNodes neînrudite, în timp ce în înaltă disponibilitate, sunt disponibile doar două NameNodes asociate, active și standby, care funcționează continuu.
NameNodes din federație partajează un pool de metadate, fiecare NameNode având pool-ul său dedicat. În High Availability, totuși, NameNodes-urile active rulează fiecare pe rând, în timp ce NameNodes-ul de așteptare rămân inactiv și își actualizează metadatele doar ocazional.
Cum să găsiți starea blocurilor și sănătatea sistemului de fișiere?
Răspuns: Utilizați comanda hdfs fsck / atât la nivel de utilizator rădăcină, cât și la un director individual pentru a verifica starea de sănătate a sistemului de fișiere HDFS.
Comanda HDFS fsck în uz:
hdfs fsck / -files --blocks –locations> dfs-fsck.log
Descrierea comenzii:
- -fișiere: imprimați fișierele pe care le verificați.
- –locations: Tipărește locațiile tuturor blocurilor în timpul verificării.
Comanda pentru a verifica starea blocurilor:
hdfs fsck <path> -files -blocks
: Începe verificările din calea trecută aici. - – blocuri: imprimă blocurile de fișiere în timpul verificării
Când utilizați comenzile rmadmin-refreshNodes și dfsadmin-refreshNodes?
Răspuns: Aceste două comenzi sunt utile în reîmprospătarea informațiilor despre nod fie în timpul punerii în funcțiune, fie când punerea în funcțiune a nodului este finalizată.
Comanda dfsadmin-refreshNodes rulează clientul HDFS și reîmprospătează configurația nodului NameNode. Comanda rmadmin-refreshNodes, pe de altă parte, execută sarcinile administrative ale ResourceManager.
Ce este un punct de control?
Răspuns: Punctul de control este o operațiune care îmbină ultimele modificări ale sistemului de fișiere cu cea mai recentă FSImage, astfel încât fișierele jurnal de editare să rămână suficient de mici pentru a accelera procesul de pornire a unui NameNode. Punctul de control are loc în NameNode secundar.
De ce folosim HDFS pentru aplicații care au seturi mari de date?
Răspuns: HDFS oferă o arhitectură DataNode și NameNode care implementează un sistem de fișiere distribuit.
Aceste două arhitecturi oferă acces de înaltă performanță la date prin clustere foarte scalabile de Hadoop. NameNode-ul său stochează metadatele sistemului de fișiere în RAM, ceea ce duce la limitarea cantității de memorie a numărului de fișiere HDFS.
Ce face comanda „jps”?
Răspuns: Comanda Java Virtual Machine Process Status (JPS) verifică dacă anumiți demoni Hadoop, inclusiv NodeManager, DataNode, NameNode și ResourceManager, rulează sau nu. Această comandă este necesară pentru a rula de la rădăcină pentru a verifica nodurile de operare din gazdă.
Ce este „Execuția speculativă” în Hadoop?
Răspuns: Acesta este un proces în care nodul principal din Hadoop, în loc să repare sarcinile lente detectate, lansează o instanță diferită a aceleiași sarcini ca o sarcină de rezervă (sarcină speculativă) pe un alt nod. Execuția speculativă economisește mult timp, mai ales într-un mediu de lucru intens.
Numiți cele trei moduri în care Hadoop poate rula.
Răspuns: Cele trei noduri principale pe care rulează Hadoop includ:
- Standalone Node este modul implicit care rulează serviciile Hadoop folosind FileSystem local și un singur proces Java.
- Pseudo-distribuit Node execută toate serviciile Hadoop folosind o singură implementare Hadoop.
- Nodul complet distribuit rulează servicii Hadoop master și slave folosind noduri separate.
Ce este un UDF?
Răspuns: UDF (Funcții definite de utilizator) vă permite să codificați funcțiile personalizate pe care le puteți utiliza pentru a procesa valorile coloanelor în timpul unei interogări Impala.
Ce este DistCp?
Răspuns: DistCp sau Distributed Copy, pe scurt, este un instrument util pentru copierea mare între sau intra-cluster a datelor. Folosind MapReduce, DistCp implementează eficient copia distribuită a unei cantități mari de date, printre alte sarcini precum gestionarea erorilor, recuperarea și raportarea.
Răspuns: Hive metastore este un serviciu care stochează metadatele Apache Hive pentru tabelele Hive într-o bază de date relațională precum MySQL. Oferă API-ul serviciului metastore care permite accesul centului la metadate.
Definiți RDD.
Răspuns: RDD, care înseamnă Resilient Distributed Datasets, este structura de date a Spark și o colecție distribuită imuabilă a elementelor dvs. de date care calculează pe diferite noduri ale clusterului.
Cum pot fi incluse bibliotecile native în joburile YARN?
Răspuns: Puteți implementa acest lucru fie folosind -Djava.library. opțiunea cale din comandă sau setând LD+LIBRARY_PATH în fișierul .bashrc folosind următorul format:
<property> <name>mapreduce.map.env</name> <value>LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/my/libs</value> </property>
Explicați „WAL” în HBase.
Răspuns: Write Ahead Log (WAL) este un protocol de recuperare care înregistrează modificările datelor MemStore din HBase în stocarea bazată pe fișiere. WAL recuperează aceste date dacă RegionalServer se blochează sau înainte de a spăla MemStore.
Este YARN un înlocuitor pentru Hadoop MapReduce?
Răspuns: Nu, YARN nu este un înlocuitor Hadoop MapReduce. În schimb, o tehnologie puternică numită Hadoop 2.0 sau MapReduce 2 acceptă MapReduce.
Care este diferența dintre ORDER BY și SORT BY în HIVE?
Răspuns: În timp ce ambele comenzi preiau datele într-un mod sortat în Hive, rezultatele din utilizarea SORT BY pot fi ordonate doar parțial.
În plus, SORT BY necesită un reductor pentru a ordona rândurile. Acești reductori necesari pentru ieșirea finală pot fi, de asemenea, multipli. În acest caz, rezultatul final poate fi comandat parțial.
Pe de altă parte, ORDER BY necesită doar un reductor pentru o comandă totală în ieșire. De asemenea, puteți utiliza cuvântul cheie LIMIT care reduce timpul total de sortare.
Care este diferența dintre Spark și Hadoop?
Răspuns: În timp ce atât Hadoop, cât și Spark sunt cadre de procesare distribuite, diferența lor cheie este procesarea lor. Acolo unde Hadoop este eficient pentru procesarea în lot, Spark este eficient pentru procesarea datelor în timp real.
În plus, Hadoop citește și scrie în principal fișiere pe HDFS, în timp ce Spark folosește conceptul Resilient Distributed Dataset pentru a procesa datele în RAM.
Pe baza latenței lor, Hadoop este un cadru de calcul cu latență mare, fără un mod interactiv de procesare a datelor, în timp ce Spark este un cadru de calcul cu latență scăzută care procesează datele în mod interactiv.
Comparați Sqoop și Flume.
Răspuns: Sqoop și Flume sunt instrumente Hadoop care adună date colectate din diverse surse și le încarcă în HDFS.
- Sqoop(SQL-to-Hadoop) extrage date structurate din baze de date, inclusiv Teradata, MySQL, Oracle etc., în timp ce Flume este util pentru extragerea datelor nestructurate din sursele bazei de date și încărcarea lor în HDFS.
- În ceea ce privește evenimentele determinate, Flume este condus de evenimente, în timp ce Sqoop nu este condus de evenimente.
- Sqoop utilizează o arhitectură bazată pe conectori în care conectorii știu cum să se conecteze la o sursă de date diferită. Flume folosește o arhitectură bazată pe agenți, codul scris fiind agentul responsabil de preluarea datelor.
- Datorită naturii distribuite a lui Flume, poate colecta și agrega cu ușurință date. Sqoop este util pentru transferul de date paralel, ceea ce duce la ieșirea în mai multe fișiere.
Explicați BloomMapFile.
Răspuns: BloomMapFile este o clasă care extinde clasa MapFile și folosește filtre dinamice de înflorire care oferă un test rapid de apartenență pentru chei.
Enumerați diferența dintre HiveQL și PigLatin.
Răspuns: În timp ce HiveQL este un limbaj declarativ similar cu SQL, PigLatin este un limbaj procedural de flux de date de nivel înalt.
Ce este curățarea datelor?
Răspuns: Curățarea datelor este un proces crucial de eliminare sau remediere a erorilor de date identificate, care includ date incorecte, incomplete, corupte, duplicate și formatate greșit dintr-un set de date.
Acest proces urmărește să îmbunătățească calitatea datelor și să ofere informații mai precise, consecvente și fiabile necesare pentru luarea deciziilor eficiente în cadrul unei organizații.
Concluzie💃
Odată cu creșterea actuală a oportunităților de angajare în Big Data și Hadoop, poate doriți să vă sporiți șansele de a intra. Întrebările și răspunsurile la interviul Hadoop din acest articol vă vor ajuta să obțineți acel interviu viitor.
Apoi, puteți consulta resurse bune pentru a învăța Big Data și Hadoop.
Mult noroc! 👍