

Un plan de recuperare în caz de dezastru este o măsură principală pe care o organizație trebuie să o aibă înainte ca un eveniment neobișnuit să o lovească.
În industria IT, începe prin crearea unui document oficial care conține planuri, acțiuni și proceduri privind gestionarea dezastrului și a efectelor sale secundare.
Dezastrul este un eveniment care vine brusc, fără notificare prealabilă și poate fi de diferite tipuri. Și atunci când aterizează, indivizii și organizațiile se confruntă cu dificultăți de mai multe feluri, inclusiv probleme financiare și experiența utilizatorului.
Dacă are loc un atac, trebuie să fiți pregătit să minimizați efectele acestuia și să vă restabiliți operațiunile mai rapid. Aici pregătirea unui plan practic de recuperare în caz de dezastru vă va ajuta să rețineți sau să preveniți dezastrul. De asemenea, puteți reduce efectele sale secundare în ceea ce privește experiența utilizatorului, costul și timpul de nefuncționare.
În plus, trebuie să vă păstrați planurile, oamenii, strategiile, echipamentele și sistemele pregătite pentru a pune totul din nou în acțiune. Dar pentru aceasta, trebuie să înțelegeți în profunzime recuperarea în caz de dezastru.
În acest articol, voi discuta acest lucru în detaliu, împreună cu terminologiile cheie de recuperare în caz de dezastru, astfel încât să puteți riposta cu curaj și să ieșiți mai puternic în astfel de condiții adverse.
Sa incepem!
Cuprins
Ce este un dezastru?
Un dezastru este un eveniment neprevăzut care se poate întâmpla oriunde, inclusiv în industria IT. Apare fie în mod natural, fie de către oameni și poate interfera cu operațiunile unei companii și poate perturba structura infrastructurii.
Ca rezultat, o organizație și clienții, vânzătorii, angajații și partenerii săi sunt afectați. Aceasta pune presiune asupra organizației în ceea ce privește finanțele, reputația industriei, încrederea clienților și perimetrul de securitate.
Prin urmare, trebuie să fiți pregătit în avans pentru a depăși un astfel de scenariu. Pentru aceasta, trebuie să recuperați instantaneu fiecare operațiune și date. Cu cuvinte simple, trebuie să vă pregătiți organizația pentru a recupera totul în cel mai scurt interval posibil pentru clienții dvs.
Dezastrele sunt de multe tipuri, cum ar fi atacuri cibernetice, sabotaj, atacuri teroriste, ransomware sau amenințări fizice, uragane, cutremure, incendii, inundații, accidente industriale, pene de curent și multe altele.
Ce înțelegeți prin recuperare în caz de dezastru?

Recuperarea în caz de dezastru este procesul de refacere a operațiunilor normale după ce a suferit un dezastru. Aceasta implică reluarea accesului la hardware, software, echipamente, conectivitate, rețea, putere și date. Trebuie să stabiliți reguli și proceduri într-un proces documentat pentru a vă pregăti organizația înainte de un dezastru.
Cu toate acestea, dacă facilitățile organizației dvs. sunt distruse, trebuie să extindeți unele dintre activități lucrând la comunicare, transport, aprovizionare, locații de lucru și multe altele.
De ce este important planul de recuperare în caz de dezastru?
Elaborarea unui plan perfect de recuperare după un dezastru, fie natural, fie provocat de om, este esențială pentru fiecare industrie IT. Asigurați-vă că aveți angajatul și instrumentele potrivite la locul potrivit pentru a realiza planul fără probleme.
Să ne aprofundăm de ce este crucială recuperarea în caz de dezastru.
Limitați daunele
Un dezastru este imprevizibil. Nimeni nu știe când vine și pleacă. Dar, vă pregătiți din timp pentru a controla daunele cauzate infrastructurii dumneavoastră.
De exemplu, în zonele predispuse la inundații, puteți plasa documentele esențiale și tipurile de echipamente la ultimul etaj pentru a evita deteriorarea.
În mod similar, faceți o copie de rezervă a datelor esențiale înainte ca atacurile cibernetice să le poată încălca sau să le fure.
Servicii de restaurare
Dacă pregătiți un plan solid pentru recuperarea după dezastru, restabilirea tuturor serviciilor la forma lor normală este rapidă și ușoară. Înseamnă că într-un interval scurt de timp, puteți recupera aproape toate activele și serviciile majore.
Minimizați întreruperile
Nu poți ști ce se va întâmpla mâine sau în următorul pas al unei operații. Dar, cu un plan de recuperare perfect, nu trebuie să vă îngrijorați prea mult de consecințe. Infrastructura dumneavoastră poate continua operațiunile cu întreruperi minime.
Instruire și Pregătire

O infrastructură IT constă din mulți angajați care lucrează sub un acoperiș. Toți trebuie să știe despre recuperare pentru a acționa imediat după cum este necesar și așteptat în caz de urgență.
Pregătirea adecvată va reduce, de asemenea, nivelul de stres al tuturor celor asociați cu organizația dvs. În plus, vă puteți instrui angajații pentru a lua măsurile necesare în cazul în care apare un eveniment neașteptat.
Terminologii de recuperare în caz de dezastru
Să începem cu terminologiile pentru a înțelege recuperarea în caz de dezastru dintr-o vedere mai atentă.
RTO
Recovery Time Objective (RTO) este perioada de timp pe care o organizație o stabilește în funcție de natura afacerii pentru a tolera dezastrul fără a afecta creșterea financiară.
În timp ce setează RTO, o companie trebuie să verifice timpii de nefuncționare care vă pot afecta organizația în multe feluri. Este folosit pentru a studia strategii viabile pentru a-ți continua operațiunile de afaceri chiar și după un dezastru. Când clienții se confruntă cu orice perturbări în aplicație, ei întreabă cât timp va dura o aplicație pentru a reveni la acțiune. Răspunsul este RTO pentru fiecare organizație.
Exemplu: Să presupunem că sunteți o companie de tranzacții online precum PayPal sau Pioneer, care se confruntă cu evenimente imprevizibile. În acest caz, RTO va fi suficient de rapid pentru a recupera operațiunea.
Cu alte cuvinte, o companie își stabilește RTO la o oră sau două pentru a evita consecințele sub formă de finanțare sau date.
RPO
Recovery Point Objectives (RPO) este pierderea de date pe care o poate gestiona o infrastructură IT în ceea ce privește timpul și cantitatea de informații.
Confuz?
Luați un exemplu de bază de date care înregistrează tranzacțiile unei bănci, inclusiv transferurile, programarea, plățile și multe altele. Când are loc un dezastru, baza de date este recuperată în timp real. Diferența dintre baza de date în momentul dezastrului și recuperarea bazei de date după un dezastru este zero în acest caz.
Pentru unele companii, este acceptabil să dureze aproximativ 24 de ore pentru a recupera toate informațiile din backup, dar poate fi catastrofal uneori. Este esențial să vă setați infrastructura conform cerințelor RPO. Aceasta include creșterea frecvenței backup-urilor, adăugarea unei baze de date de așteptare în arhitectura dvs. și multe altele.
Failover
Gândiți-vă la o situație în care călătoriți pe distanțe lungi. Dintr-o dată, ai o anvelopă deflată din cauza unui motiv neașteptat. Vă mulțumiți pentru anvelopa de rezervă disponibilă în vehiculul dumneavoastră și pentru instrumentele necesare pentru a schimba anvelopa defecte.
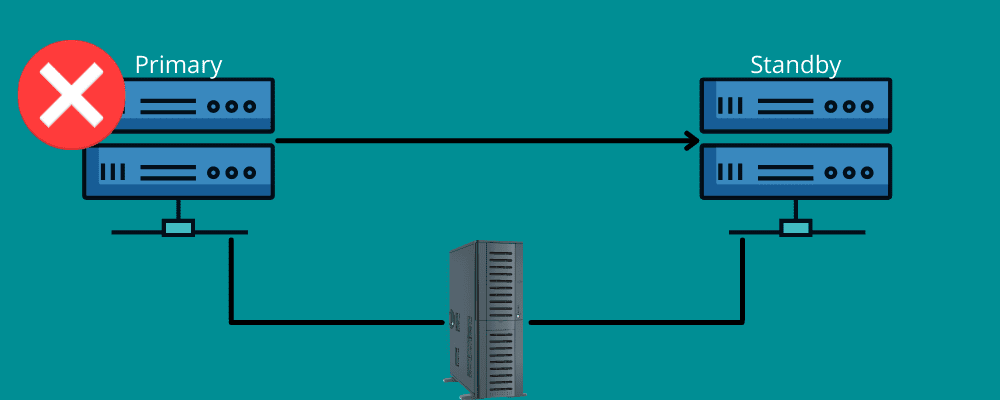
Failover-ul funcționează în același mod.
Înseamnă că aveți nevoie de o conexiune de rezervă în timpul dezastrului. Pe scurt, failover-ul înseamnă să aveți rețele și sisteme pe care le puteți utiliza în momentul unui dezastru pentru a vă comuta informațiile în sistemul de recuperare.
Failover vă asigură că toate serviciile dumneavoastră funcționează fără probleme, chiar dacă există defecțiuni de infrastructură sau hardware. În acest fel, puteți împiedica organizația dvs. să piardă date și venituri și să evitați întreruperile serviciilor pentru utilizatorii dvs. finali.
Puteți fie să îl setați manual, fie să îi permiteți să funcționeze automat pentru a muta datele pe serverul de așteptare.
Failback
Efectuarea failback-ului IT este o operațiune simplă în care producția inițială revine la locul inițial (sistemul) după ce este tratat un dezastru. În timpul atacului, companiile urmează o operațiune de failover datorită căreia toate sarcinile de lucru sunt transferate într-o replică VM sau un sistem de rezervă.
Cu toate acestea, nu puteți sări peste următorul pas de întoarcere. Când recuperați totul și reveniți la acțiune, trebuie să transferați toate sarcinile de lucru pe mașinile virtuale sau sistemele lor originale. Acest proces general de returnare a sarcinilor de lucru la locul de muncă sau sistemul original este cunoscut sub numele de failback. Înseamnă că te întorci „înapoi” după atac.
Failback-ul este, de asemenea, utilizat pentru întreținerea programată a unei întreprinderi. Este adevărat că failback-ul are loc întotdeauna după failover. Cu alte cuvinte, failover-ul este primul pas, iar failback-ul este al doilea pas în recuperarea datelor esențiale. Poate fi configurat de la cloud la cloud, de la local la local, de la local la cloud sau orice combinație dintre acestea.
DR
Recuperarea în caz de dezastru (DR) este procesul prin care aveți planuri pre-construite pentru a vă recupera activele în intervalul de timp.
DR oferă unei organizații capacitatea de a răspunde rapid și de a recupera fiecare serviciu de la un eveniment neașteptat. De asemenea, oferă documentație oficială care conține instrucțiuni privind luarea de măsuri imediate în cazul unor incidente neprevăzute.
BCP
Planul de continuitate a afacerii (BCP) este unul dintre cele mai acceptabile planuri de recuperare în caz de dezastru, care permite infrastructurii IT să facă strategii pentru a gestiona întreruperile IT la servere, dispozitive mobile, computere personale și rețele.
BCP este ușor diferit de recuperarea în caz de dezastru, deoarece ajută o organizație să facă planuri pentru a restabili software-ul și productivitatea întreprinderii pentru a satisface nevoile cheie ale afacerii.
Aici, o companie creează un sistem de recuperare pentru a depăși potențialele amenințări, cum ar fi atacurile cibernetice sau dezastrele naturale. Este conceput pentru a securiza activele și pentru a se asigura că toate serviciile vor reveni rapid în acțiune după grevă.
BCM

Managementul continuității afacerii (BCM) este un proces de management al riscului special conceput pentru a acționa ca un scut împotriva amenințărilor la adresa proceselor de afaceri. BCM este următorul pas al BCP, în care validează planurile de recuperare pentru a se asigura că toată lumea din afacere răspunde instantaneu la plan și recuperează toate lucrurile esențiale.
BCM acționează ca un cadru de management pentru a identifica riscurile de infrastructură atunci când se confruntă cu amenințări externe și/sau interne. De asemenea, se asigură că cadrul funcționează eficient cu ajutorul testării regulate pentru a îmbunătăți predictibilitatea, a reduce riscul și a alinia planul pentru atacurile viitoare.
BIA
Analiza impactului asupra afacerii (BIA) este procesul de analiză a ratei de supraviețuire a unei afaceri prin identificarea sistemelor, operațiunilor și proceselor esențiale. Acesta spune despre efectul unui dezastru asupra organizației dvs. din cauza întreruperii operațiunilor dumneavoastră.
BIA prezice consecințele înainte ca un atac să aibă loc efectiv pentru a colecta informații cheie care pot ajuta la crearea unor strategii puternice de recuperare. De asemenea, identifică costul implicat din cauza defecțiunilor, cum ar fi costul de înlocuire al echipamentului, pierderea fluxului de numerar, profituri, salarii și multe altele.
Atunci când creați un raport BIA, trebuie să luați în considerare procesele cruciale implicate în afacerea dvs., impactul întrerupțiilor asupra diferitelor domenii, durata acceptabilă, zonele tolerabile, costurile financiare și multe altele.
Apelează Tree
Un arbore de apeluri este un proces de pregătire a unei liste de personal la care să apelați în timpul unei urgențe. Este o procedură care urmează o structură arborescentă.
De exemplu, în timpul unui dezastru, o persoană va contacta un grup mic de membri cu un mesaj urgent, acei membri ai personalului apelând fiecare grup separat. În acest fel, tot personalul va fi informat în timpul amenințării și va începe slujba atribuită pentru a recupera fiecare funcție și proces la timp. Realizarea unei liste este simplă, dar implementarea ei în timp real creează confuzie.
Trebuie să efectuați activități regulate de apel pentru a pregăti fiecare membru al personalului de urgență să rămână alert. Testarea regulată poate ajuta, de asemenea, la identificarea numerelor modificate sau lipsă care pot afecta grav performanța.
Un arbore de apeluri conține informații care trebuie utilizate în timpul unei urgențe pentru a furniza instrucțiuni. Se poate face și manual, dar oamenii folosesc automatizarea pentru a accelera procesul și pentru a notifica membrii în lumea digitală de astăzi.
Centru de comandă/Centrul de control
Este o facilitate virtuală sau fizică special pregătită pentru a oferi comandă sau control asupra planurilor de recuperare în timpul unei crize. Comunică cu echipa pentru a gestiona sistemele și funcțiile în timpul dezastrului.
În mod tradițional, infrastructura depinde de centrul de comandă care se ocupă de crize fără nicio abordare adecvată. În zilele noastre, organizațiile și-au proiectat perfect centrul de control, ceea ce transformă răspunsul imediat în competența de bază.
Odată ce simte un dezastru, centrul de comandă se îndreaptă rapid către faza de recuperare. Mai mult, servește ca punct de raportare în cazul serviciilor, presei, livrărilor și multe altele. De asemenea, reunește oameni din mai multe discipline în astfel de scenarii.
Răspuns la incident

Răspunsul la incident este un tip de răspuns dat pentru a face față unui atac. Se realizează cu ajutorul procedurilor și al personalului potrivit pentru a păstra securitatea rețelei și a datelor în mod eficient, la momentul potrivit.
Dacă o organizație are un plan de incident înainte de evenimentul neașteptat, își poate securiza datele de amenințări în timp real. Specialiștii în răspunsul la incident rămân mereu atenți la probleme și acționează natural în timpul unui incident. Ei iau anumite măsuri pentru a evita încălcările de securitate, asigurându-se că nu opresc niciun pas în timpul recuperării în caz de dezastru.
La început, trebuie să determinați datele critice și să le stocați în cloud sau în orice locație la distanță pentru a asigura siguranță. Abordați nevoile actuale de infrastructură și amenințările cibernetice în evoluție, actualizând în mod regulat planurile de răspuns la incidente.
Backup
Soluțiile de backup ajută o infrastructură IT să mențină copiile datelor și să le stocheze în siguranță la momentul potrivit. Dacă vă confruntați cu coruperea bazei de date, ștergerea accidentală a tuturor datelor sau orice altă problemă, trebuie să fiți pregătit cu copierea de rezervă pentru a restaura datele instantaneu și a continua cu serviciile.

Aceasta implică replicarea fișierelor și stocarea lor într-o locație sigură pentru a accesa toate datele cu ușurință după un eveniment neobișnuit. Vă va ajuta dacă faceți copii de rezervă ale datelor în mai multe locații pentru a vă asigura că le puteți restaura chiar dacă un site eșuează.
Reziliență
Capacitatea comunităților, statelor, organizațiilor și indivizilor de a rezista sau de a rezista unui dezastru fără a compromite serviciile și sistemele este cunoscută sub numele de rezistență la dezastre.
O organizație trebuie să fie pregătită să rețină o cantitate mare de stres din cauza pericolelor. Asigurați-vă că aveți capabilitățile de a vă minimiza pierderile cu o planificare mai bună, în loc să așteptați ca cineva să vină să vă salveze. Acest lucru vă va ajuta să faceți față dezastrelor și să vă recuperați eficient infrastructura IT.
Aici, scopul principal este conservarea și restaurarea funcțiilor și structurilor esențiale la momentul potrivit ori de câte ori este necesar. Pentru a deveni o organizație rezistentă la dezastre, trebuie să vă pregătiți în avans și să aveți capacitatea de a anticipa riscurile, de a vă adapta la schimbări, de a împărtăși și de a învăța, de a integra diverse sectoare și de a gestiona nivelurile de risc.
SLA

Acordul privind nivelul de servicii (SLA) este un plan de dezastru în care menționați utilizatorilor finali timpul pe care îl puteți lua pentru a restabili serviciile în timpul unei urgențe.
SLA asigură clienților că datele lor sunt în siguranță și nu sunt compromise sau partajate cu terțe părți. Este singurul punct de contact cu problemele utilizatorilor finali.
Fiecare infrastructură IT oferă clienților săi asigurări cu privire la SLA. Deci, asigurați-vă că comunicați cu utilizatorii finali în prealabil.
SPOF
Un Single Point of Failure (SPOF) este un echipament, un individ, o resursă sau o aplicație la care sunt conectate multe alte sisteme sau aplicații.
Dacă un astfel de echipament sau resursă se prăbușește, toate piesele esențiale conectate la sistem se prăbușesc odată cu ea. Astfel, întregul proces și operațiunea afacerii vor fi afectate.
Prin urmare, trebuie să aveți o strategie pentru a gestiona o astfel de problemă pentru a vă menține organizația în funcțiune. Primul lucru pe care îl puteți face este să identificați acel singur echipament sau sistem care poate avea un impact mai mare. Apoi, rulați o analiză a impactului asupra afacerii și obțineți un scor de evaluare a riscurilor pentru a fi conștienți de scenele care vor avea loc. Sapă și găsește-le înainte de eveniment.
Odată ce enumerați toate SPOF, clasificați-le în funcție de procesul de recuperare. Puneți fiecare dintre SPOF în trei categorii diferite:
- Recuperați ușor și direct, cu mai puțin timp și buget.
- Recuperarea ar fi dificilă, dar ar putea fi dezvoltat un proces de încredere pentru restaurare.
- Nu se poate face nimic pentru a vă recupera odată ce acesta scade.
Puteți acționa în consecință în funcție de categorie.
Recuperare sistem
În timpul defecțiunii hardware, trebuie să rulați un proces de recuperare pentru a prelua un anumit sistem sau server la forma sa originală. Și pentru a recupera întregul sistem, trebuie să fiți pregătit cu cerințele de recuperare, backup-uri, compatibilitate cu firmware-ul și compatibilitate hardware.
Recuperarea sistemului este un proces care resetează mașina la setările anterioare sau în aceeași stare în care era când era nou. Dacă faceți acest lucru, veți șterge toate infecțiile cu virusuri datorate software-ului sau aplicațiilor instalate în sistemul dvs.
Acest proces include planificarea recuperării unei infrastructuri IT care stabilește și urmează anumite proceduri pentru a asigura disponibilitatea datelor împotriva perturbărilor provocate de om sau naturale.
Restaurarea sistemului
Restaurarea sistemului este un instrument de recuperare care vă permite să restaurați anumite fișiere și informații la starea anterioară la momentul potrivit.
Cu restaurarea sistemului, puteți recupera cheile de registry, programele instalate, driverele, fișierele de sistem și multe altele înapoi la versiunea anterioară. Acesta acționează ca un salvator în multe dezastre.
Planul de testare
Se referă la un document care stochează informații despre o strategie de testare, estimări, resurse, termene limită, obiective și calendare. Funcționează ca un model care rulează teste pentru a asigura siguranța hardware și software.
Aceasta include diverse teste în conformitate cu procedurile și pașii planificați pentru a gestiona efectele dezastrelor. Efectuați testele regulate pentru a vă pregăti pe dumneavoastră și organizația dumneavoastră să nu săriți niciun pas în timpul acțiunii. În acest fel, o infrastructură IT poate înțelege deficiențele și poate fi pregătită pentru luptă.
Concluzie
Nimeni nu știe când se va întâmpla un dezastru. Prin urmare, măsurile adecvate de siguranță și securitate sunt esențiale pentru fiecare afacere.
Terminologia de recuperare în caz de dezastru vă va ajuta să înțelegeți cum să răspundeți la atacuri și dezastre. De asemenea, vă va ajuta să vă pregătiți în avans, astfel încât să vă puteți proteja infrastructura în timpul unui eveniment neașteptat. Veți putea crea o strategie eficientă, în timp real de recuperare în caz de dezastru, pentru a economisi milioane de dolari și pentru a reține încrederea clienților.