

La 1 septembrie 2020, NVIDIA a dezvăluit noua sa gamă de GPU-uri pentru jocuri: seria RTX 3000, bazată pe arhitectura lor Ampere. Vom discuta despre noutățile, despre software-ul bazat pe inteligență artificială care vine cu el și despre toate detaliile care fac această generație cu adevărat minunată.
Cuprins
Faceți cunoștință cu GPU-urile din seria RTX 3000

Principalul anunț al NVIDIA a fost noile sale GPU-uri strălucitoare, toate construite pe un proces de fabricație personalizat de 8 nm și toate aducând accelerări majore atât în performanța rasterizării, cât și a urmăririi razelor.
În partea de jos a gamei, se află RTX 3070, care vine la 499 USD. Este puțin scump pentru cel mai ieftin card dezvăluit de NVIDIA la anunțul inițial, dar este o furare absolută odată ce aflați că depășește RTX 2080 Ti existent, o placă de vârf care se vinde în mod regulat cu peste 1400 USD. Cu toate acestea, după anunțul NVIDIA, prețul de vânzare terță parte a scăzut, un număr mare dintre ele fiind vândute în panică pe eBay pentru sub 600 de dolari.
Nu există puncte de referință solide de la anunț, așa că nu este clar dacă placa este într-adevăr obiectiv „mai bună” decât un 2080 Ti sau dacă NVIDIA răsucește puțin marketingul. Benchmark-urile rulate erau la 4K și probabil aveau RTX activat, ceea ce poate face ca decalajul să pară mai mare decât va fi în jocurile pur rasterizate, deoarece seria 3000 bazată pe Ampere va funcționa de peste două ori mai bine la ray tracing decât Turing. Dar, având în vedere că ray tracing-ul este acum ceva care nu afectează prea mult performanța și fiind susținut de cea mai recentă generație de console, este un motiv de vânzare major să funcționeze la fel de repede ca nava emblematică a ultimei generații pentru aproape o treime din preț.
De asemenea, nu este clar dacă prețul va rămâne așa. Modelele de la terți adaugă în mod regulat cel puțin 50 de dolari la preț și, având în vedere cât de mare va fi cererea, nu va fi surprinzător să-l vedem vânzându-se cu 600 de dolari în octombrie 2020.
Chiar deasupra se află RTX 3080 la 699 USD, care ar trebui să fie de două ori mai rapid decât RTX 2080 și să vină cu aproximativ 25-30% mai rapid decât 3080.
Apoi, la capătul de sus, noul flagship este RTX 3090, care este uriaș din punct de vedere comic. NVIDIA este bine conștientă și a numit-o „BFGPU”, despre care compania spune că înseamnă „Big Ferocious GPU”.

NVIDIA nu a arătat nicio măsurătoare de performanță directă, dar compania a arătat că rulează jocuri 8K la 60 FPS, ceea ce este serios impresionant. Desigur, NVIDIA folosește aproape sigur DLSS pentru a atinge acest punct, dar jocurile 8K sunt jocuri de 8K.
Desigur, în cele din urmă va exista un 3060 și alte variante ale cardurilor mai orientate spre buget, dar acestea vin de obicei mai târziu.
Pentru a răci lucrurile, NVIDIA avea nevoie de un design renovat de cooler. 3080 este evaluat pentru 320 de wați, ceea ce este destul de mare, așa că NVIDIA a optat pentru un design dual ventilator, dar în loc de ambele ventilatoare vwinf plasate în partea de jos, NVIDIA a pus un ventilator în partea de sus unde merge de obicei placa din spate. Ventilatorul direcționează aerul în sus către răcitorul CPU și partea superioară a carcasei.

Judecând după cât de multă performanță poate fi afectată de un flux de aer prost într-o carcasă, acest lucru este perfect logic. Cu toate acestea, placa de circuit este foarte înghesuită din această cauză, ceea ce va afecta probabil prețurile de vânzare la terți.
DLSS: Un avantaj software
Ray tracing nu este singurul beneficiu al acestor noi carduri. Într-adevăr, totul este un pic de hack – seriile RTX 2000 și seria 3000 nu sunt cu mult mai bune în a face ray tracing efectiv, în comparație cu generațiile mai vechi de carduri. Trasarea cu raze a unei scene complete în software-ul 3D precum Blender durează de obicei câteva secunde sau chiar minute pe cadru, așa că forțarea brută a acesteia în mai puțin de 10 milisecunde este exclusă.
Desigur, există hardware dedicat pentru rularea calculelor cu raze, numite nuclee RT, dar în mare măsură, NVIDIA a optat pentru o abordare diferită. NVIDIA a îmbunătățit algoritmii de eliminare a zgomotului, care permit GPU-urilor să ofere o singură trecere foarte ieftină, care arată groaznic și, cumva, prin magia AI, să transforme asta într-un ceva la care un jucător dorește să se uite. Atunci când este combinat cu tehnici tradiționale bazate pe rasterizare, oferă o experiență plăcută îmbunătățită de efectele de raytracing.

Cu toate acestea, pentru a face acest lucru rapid, NVIDIA a adăugat nuclee de procesare specifice AI numite nuclee Tensor. Acestea procesează toate calculele necesare pentru a rula modele de învățare automată și o fac foarte repede. Sunt un total schimbător de joc pentru AI în spațiul serverului cloud, deoarece AI este utilizat pe scară largă de multe companii.
Dincolo de eliminarea zgomotului, principala utilizare a nucleelor Tensor pentru jucători se numește DLSS sau deep learning super-sampling. Preia un cadru de calitate scăzută și îl crește la calitate nativă completă. Acest lucru înseamnă în esență că puteți juca cu rate de cadre la nivel de 1080p, în timp ce priviți o imagine 4K.
Acest lucru ajută, de asemenea, destul de mult la performanța ray-tracing—benchmark-uri de la PCMag Afișați un RTX 2080 Super Running Control la calitate ultra, cu toate setările de ray-tracing activate la maxim. La 4K, se luptă cu doar 19 FPS, dar cu DLSS activat, obține 54 FPS mult mai bun. DLSS este performanță gratuită pentru NVIDIA, posibilă de nucleele Tensor de pe Turing și Ampere. Orice joc care îl acceptă și este limitat de GPU poate vedea accelerări serioase doar din software.
DLSS nu este nou și a fost anunțat ca o caracteristică atunci când seria RTX 2000 a fost lansată în urmă cu doi ani. La acea vreme, era susținut de foarte puține jocuri, deoarece era necesar ca NVIDIA să antreneze și să ajusteze un model de învățare automată pentru fiecare joc individual.
Cu toate acestea, în acel timp, NVIDIA l-a rescris complet, denumind noua versiune DLSS 2.0. Este un API de uz general, ceea ce înseamnă că orice dezvoltator îl poate implementa și este deja preluat de majoritatea versiunilor majore. În loc să lucreze pe un cadru, preia date vectoriale în mișcare din cadrul anterior, în mod similar cu TAA. Rezultatul este mult mai clar decât DLSS 1.0 și, în unele cazuri, arată de fapt mai bine și mai clar decât rezoluția nativă, așa că nu există prea multe motive pentru a nu-l activa.
Există o problemă: atunci când schimbați complet scenele, ca în scenele de filmare, DLSS 2.0 trebuie să redeze primul cadru la o calitate de 50% în timp ce așteptați datele vectorului de mișcare. Acest lucru poate duce la o mică scădere a calității pentru câteva milisecunde. Dar, 99% din tot ceea ce te uiți va fi redat corect și majoritatea oamenilor nu observă acest lucru în practică.
Arhitectura Ampere: Construit pentru AI
Amperi este rapid. Serios rapid, mai ales la calculele AI. Miezul RT este de 1,7 ori mai rapid decât Turing, iar noul nucleu Tensor este de 2,7 ori mai rapid decât Turing. Combinația dintre cele două este un adevărat salt generațional în performanța raytracing.
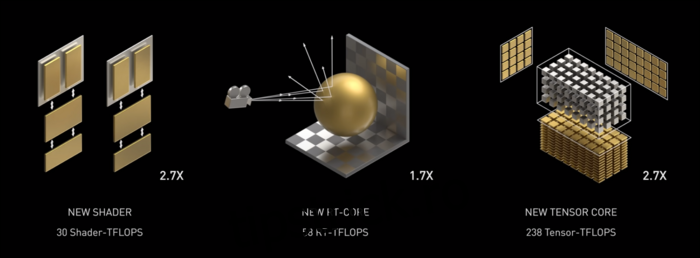
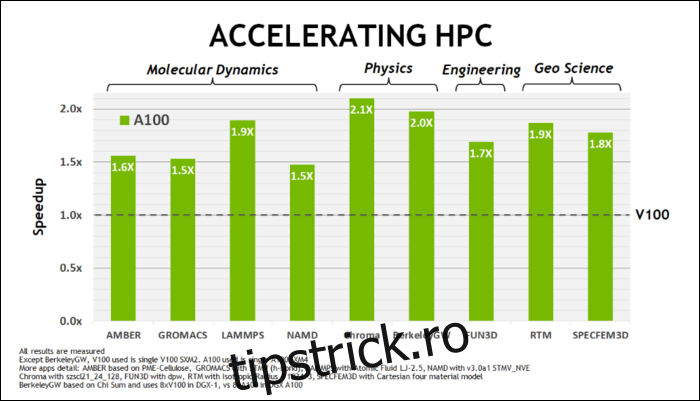
La începutul acestui mai, NVIDIA a lansat GPU-ul Ampere A100, un GPU pentru centru de date conceput pentru rularea AI. Cu el, au detaliat multe despre ceea ce face ca Ampere să fie mult mai rapid. Pentru centrele de date și sarcinile de calcul de înaltă performanță, Ampere este, în general, de aproximativ 1,7 ori mai rapid decât Turing. Pentru antrenamentul AI, este de până la 6 ori mai rapid.
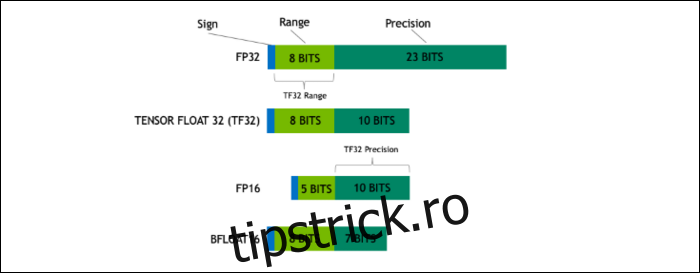
Cu Ampere, NVIDIA folosește un nou format de numere conceput pentru a înlocui standardul industrial „Floating-Point 32” sau FP32, în unele sarcini de lucru. Sub capotă, fiecare număr pe care îl procesează computerul dvs. ocupă un număr predefinit de biți în memorie, fie că este de 8 biți, 16 biți, 32, 64 sau chiar mai mare. Numerele care sunt mai mari sunt mai greu de procesat, așa că dacă puteți folosi o dimensiune mai mică, veți avea mai puțin de strâns.
FP32 stochează un număr zecimal de 32 de biți și folosește 8 biți pentru intervalul numărului (cât de mare sau mic poate fi) și 23 de biți pentru precizie. Pretenția NVIDIA este că acești 23 de biți de precizie nu sunt în întregime necesari pentru multe sarcini de lucru AI și puteți obține rezultate similare și performanțe mult mai bune din doar 10 dintre ei. Reducerea dimensiunii la doar 19 biți, în loc de 32, face o mare diferență în multe calcule.
Acest nou format se numește Tensor Float 32, iar nucleele Tensor din A100 sunt optimizate pentru a gestiona formatul de dimensiuni ciudate. Acesta este, pe lângă reducerea matrițelor și creșterea numărului de nuclee, modul în care obțin o accelerare masivă de 6 ori în antrenamentul AI.
Pe lângă noul format de numere, Ampere înregistrează creșteri majore de performanță în calcule specifice, cum ar fi FP32 și FP64. Acestea nu se traduc direct în mai multe FPS pentru neprofesionist, dar fac parte din ceea ce îl face de aproape trei ori mai rapid în general la operațiunile Tensor.

Apoi, pentru a accelera și mai mult calculele, au introdus conceptul de sparsitate structurată cu granulație fină, care este un cuvânt foarte elegant pentru un concept destul de simplu. Rețelele neuronale funcționează cu liste mari de numere, numite ponderi, care afectează rezultatul final. Cu cât mai multe numere de strâns, cu atât va fi mai lent.
Cu toate acestea, nu toate aceste numere sunt de fapt utile. Unele dintre ele sunt literalmente zero și, practic, pot fi aruncate, ceea ce duce la accelerări masive atunci când poți strânge mai multe numere în același timp. Sparsitatea comprimă în esență numerele, ceea ce necesită mai puțin efort pentru a face calcule. Noul „Sparse Tensor Core” este construit pentru a funcționa pe date comprimate.
În ciuda modificărilor, NVIDIA spune că acest lucru nu ar trebui să afecteze deloc acuratețea modelelor antrenate.
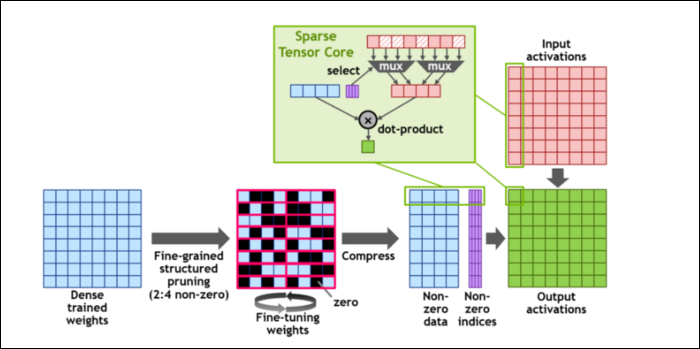
Pentru calculele Sparse INT8, unul dintre cele mai mici formate de număr, performanța de vârf a unui singur GPU A100 este de peste 1,25 PetaFLOP, un număr uluitor de mare. Bineînțeles, asta este doar atunci când scrii un anumit tip de număr, dar este totuși impresionant.