Extragerea datelor este procesul de colectare a datelor specifice din paginile web. Utilizatorii pot extrage text, imagini, videoclipuri, recenzii, produse etc. Puteți extrage date pentru a efectua cercetări de piață, analize de sentiment, analize concurente și date agregate.
Dacă aveți de-a face cu o cantitate mică de date, puteți extrage datele manual prin copierea și lipirea informațiilor specifice din paginile web într-o foaie de calcul sau în formatul de document care vă place. De exemplu, dacă, în calitate de client, căutați recenzii online pentru a vă ajuta să luați o decizie de cumpărare, puteți elimina datele manual.
Pe de altă parte, dacă aveți de-a face cu seturi mari de date, aveți nevoie de o tehnică automată de extragere a datelor. Puteți crea o soluție internă de extragere a datelor sau puteți utiliza API-ul Proxy sau API-ul Scraping pentru astfel de sarcini.
Cu toate acestea, aceste tehnici pot fi mai puțin eficiente, deoarece unele dintre site-urile pe care le vizați ar putea fi protejate prin captchas. De asemenea, poate fi necesar să gestionați roboții și proxy-urile. Astfel de sarcini vă pot ocupa mult timp și vă pot limita natura conținutului pe care îl puteți extrage.
Cuprins
Scraping Browser: Soluția
Puteți depăși toate aceste provocări prin intermediul browserului Scraping by Bright Data. Acest browser all-in-one ajută la colectarea datelor de pe site-uri web care sunt greu de răzuit. Este un browser care utilizează o interfață grafică cu utilizatorul (GUI) și este controlat de API-ul Puppeteer sau Playwright, făcându-l nedetectabil de către roboți.
Scraping Browser are funcții de deblocare încorporate care gestionează automat toate blocurile în numele tău. Browserul este deschis pe serverele Bright Data, ceea ce înseamnă că nu aveți nevoie de o infrastructură internă costisitoare pentru a elimina datele pentru proiectele dvs. la scară largă.
Caracteristicile browserului Bright Data Scraping
- Deblocare automată a site-ului web: nu trebuie să continuați să vă reîmprospătați browserul, deoarece acest browser se ajustează automat pentru a gestiona rezolvarea CAPTCHA, blocările noi, amprentele digitale și reîncercările. Scraping Browser imită un utilizator real.
- O rețea mare de proxy: puteți viza orice țară doriți, deoarece Scraping Browser are peste 72 de milioane de IP-uri. Puteți viza orașe sau chiar operatori de transport și puteți beneficia de cea mai bună tehnologie din clasă.
- Scalabil: puteți deschide mii de sesiuni simultan, deoarece acest browser utilizează infrastructura Bright Data pentru a gestiona toate solicitările.
- Compatibil cu Puppeteer și Playwright: acest browser vă permite să efectuați apeluri API și să preluați orice număr de sesiuni de browser, fie folosind Puppeteer (Python) fie Playwright (Node.js).
- Economisește timp și resurse: în loc să configureze proxy, Scraping Browser se ocupă de tot ce se află în fundal. De asemenea, nu trebuie să configurați infrastructura internă, deoarece acest instrument se ocupă de tot ce se află în fundal.
Cum se configurează Scraping Browser
- Mergeți pe site-ul Bright Data și faceți clic pe Browserul Scraping din fila „Soluții Scraping”.
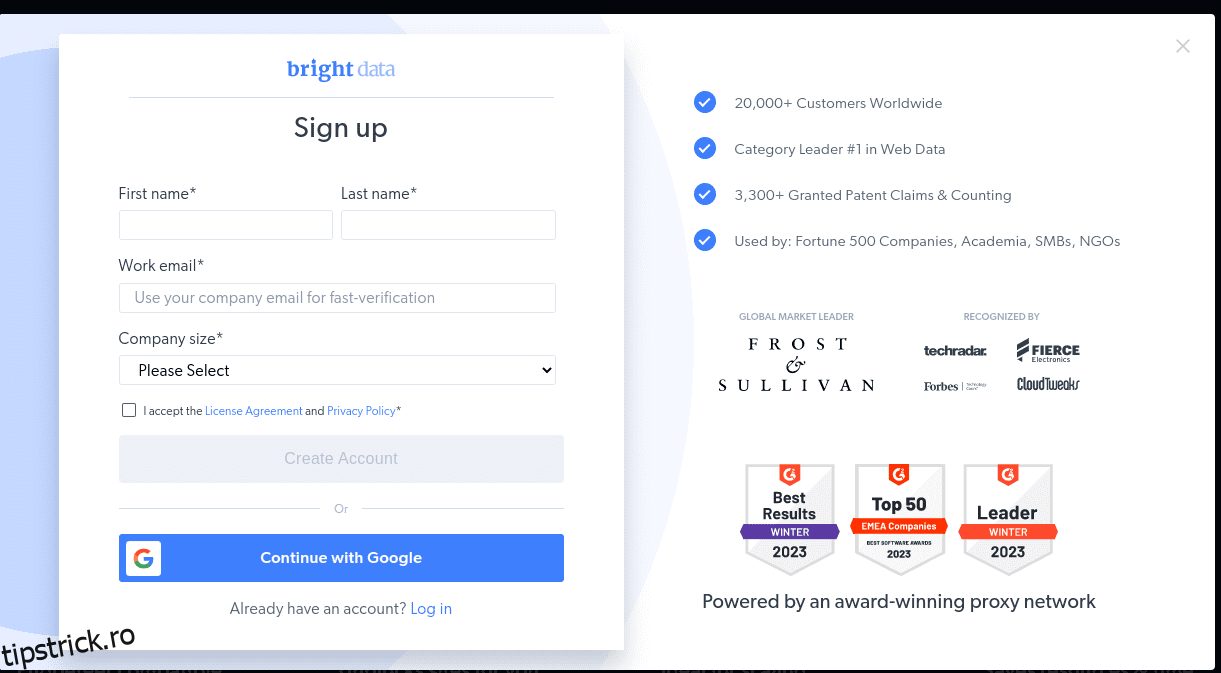
- Creați un cont. Veți vedea două opțiuni; „Începeți încercarea gratuită” și „Începeți gratuit cu Google”. Să alegem „Începe perioada de încercare gratuită” pentru moment și să trecem la pasul următor. Puteți fie să creați contul manual, fie să utilizați contul dvs. Google.
- Când contul dvs. este creat, tabloul de bord va prezenta mai multe opțiuni. Selectați „Proxies & Scraping Infrastructure”.
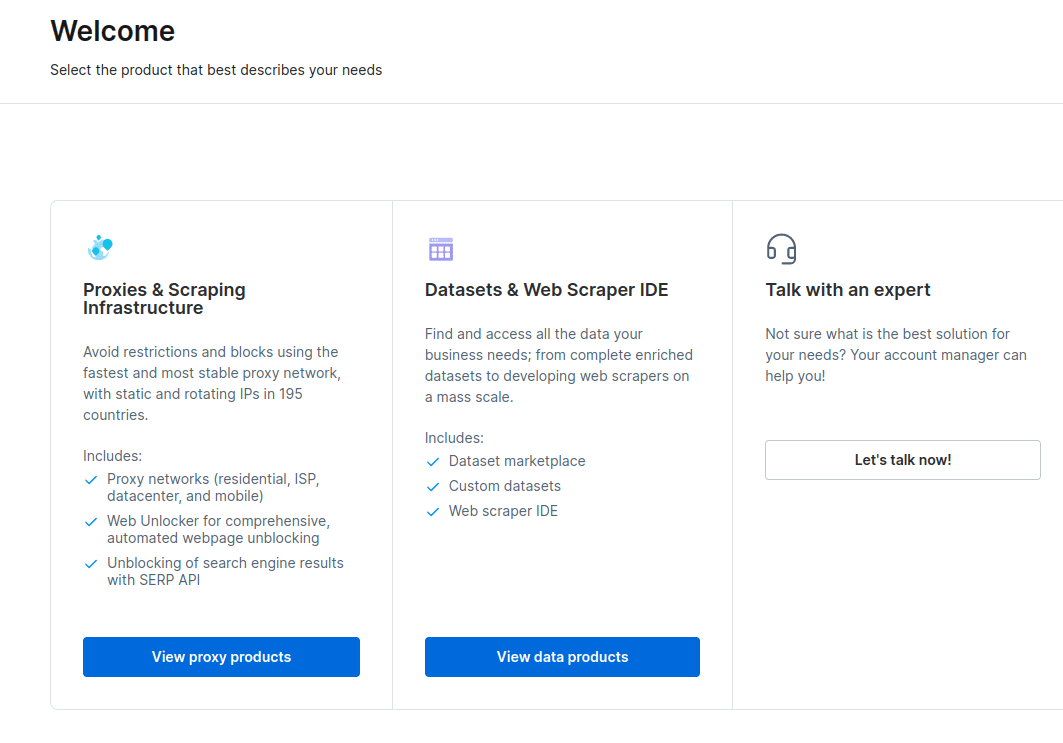
- În noua fereastră care se deschide, selectați Scraping Browser și faceți clic pe „Începeți”.
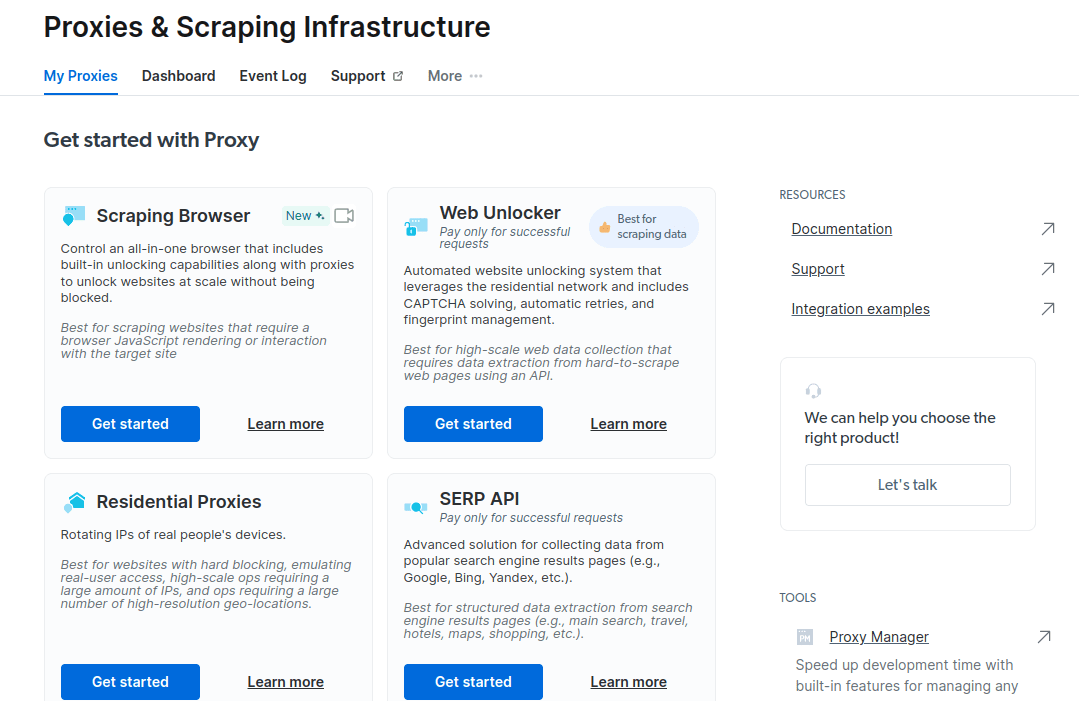
- Salvați și activați configurațiile dvs.
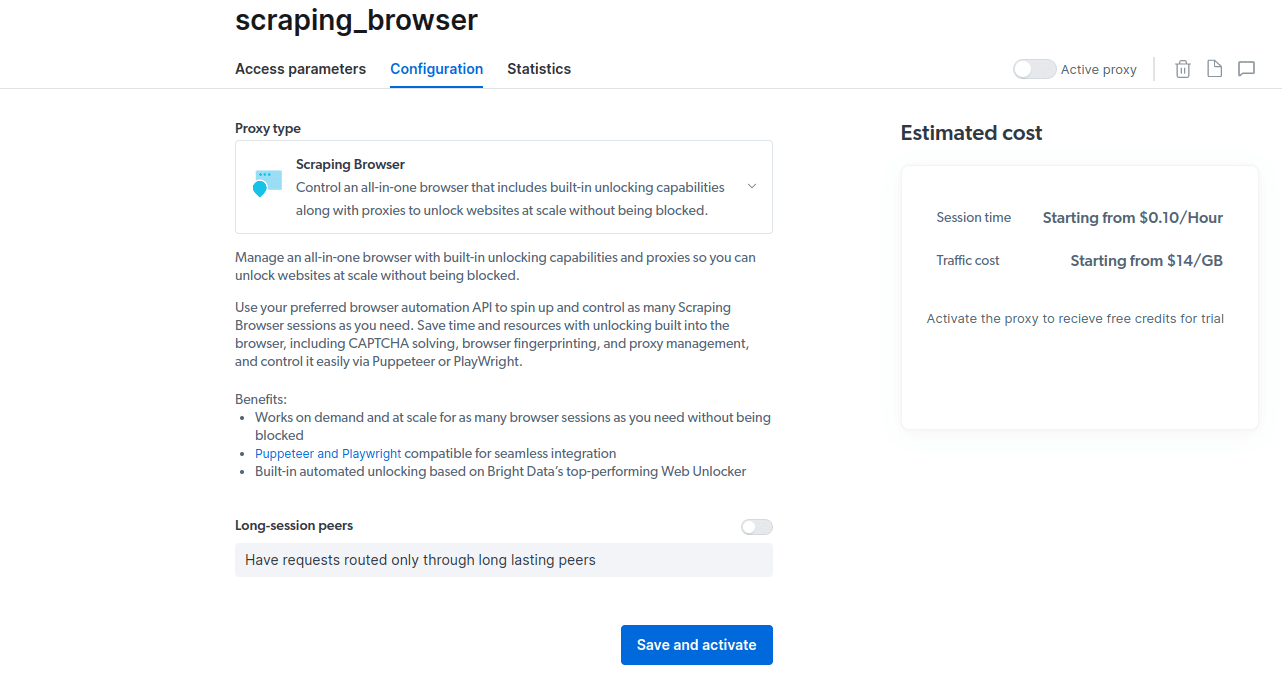
- Activați versiunea de încercare gratuită. Prima opțiune vă oferă un credit de 5 USD pe care îl puteți utiliza pentru utilizarea proxy-ului. Faceți clic pe prima opțiune pentru a încerca acest produs. Cu toate acestea, dacă sunteți un utilizator intens, puteți face clic pe a doua opțiune care vă oferă 50 USD gratuit dacă vă încărcați contul cu 50 USD sau mai mult.
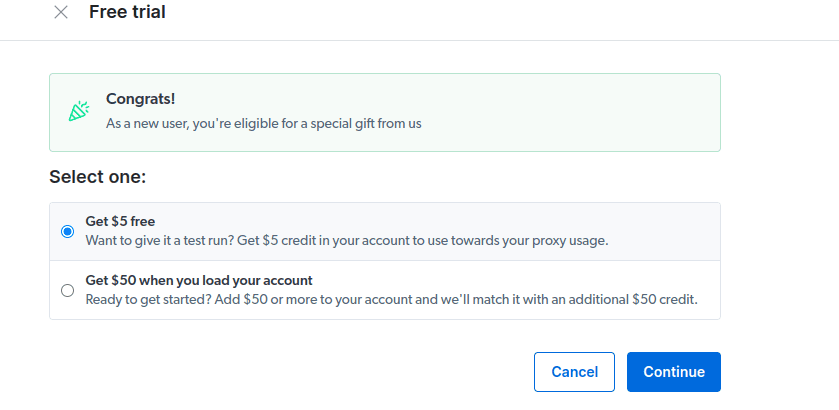
- Introduceți informațiile dvs. de facturare. Nu vă faceți griji, deoarece platforma nu vă va taxa cu nimic. Informațiile de facturare doar verifică dacă sunteți un utilizator nou și nu căutați gratuită prin crearea mai multor conturi.
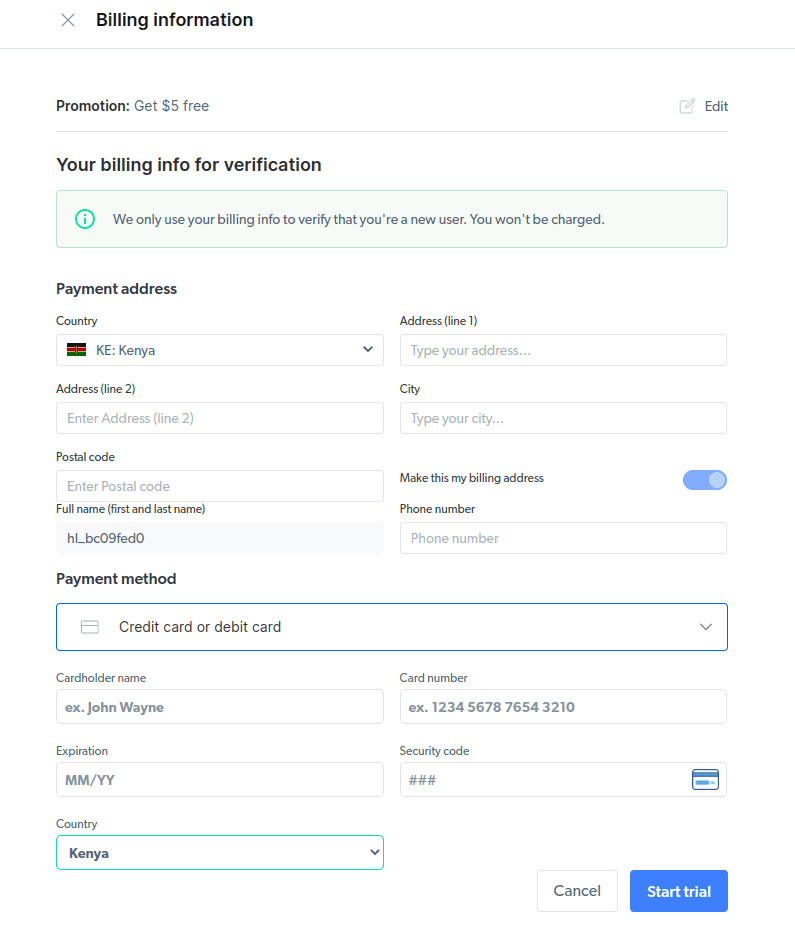
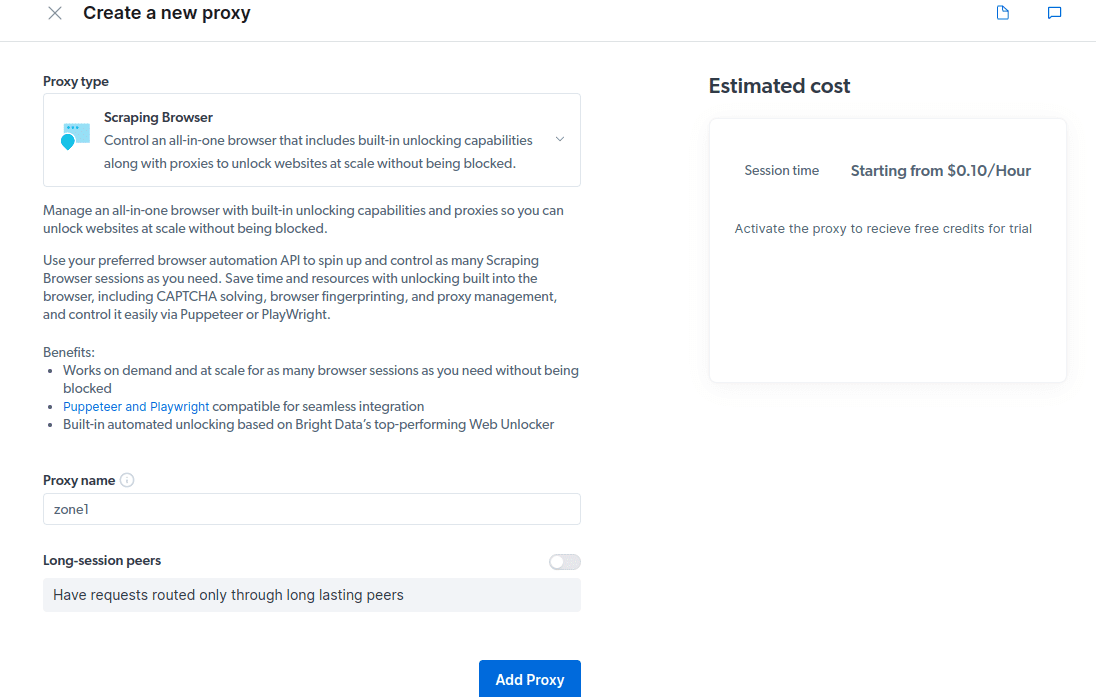
- Creați un nou proxy. După ce ați salvat detaliile de facturare, puteți crea un nou proxy. Faceți clic pe pictograma „adăugați” și selectați Scraping Browser ca „Tipul de proxy”. Faceți clic pe „Adăugați proxy” și treceți la pasul următor.
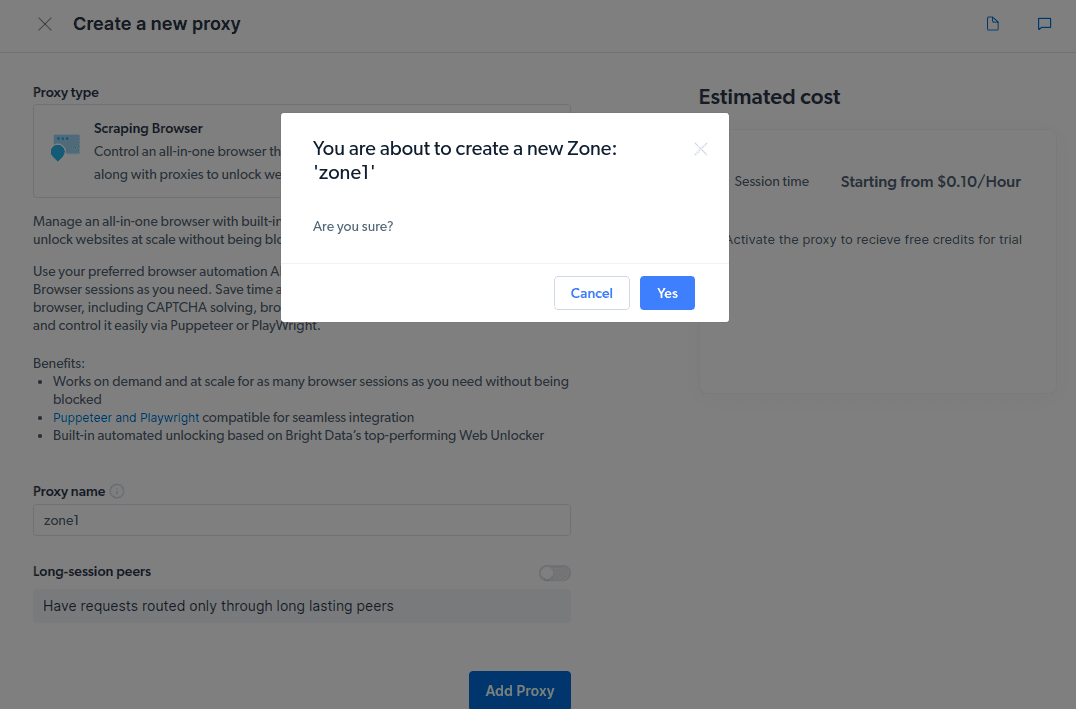
- Creați o nouă „zonă”. Va apărea un pop care vă va întreba dacă doriți să creați o zonă nouă; faceți clic pe „Da” și continuați.
- Faceți clic pe „Verificați exemple de cod și integrare”. Acum veți obține exemple de integrare proxy pe care le puteți utiliza pentru a elimina datele de pe site-ul dvs. țintă. Puteți utiliza Node.js sau Python pentru a extrage date de pe site-ul țintă.
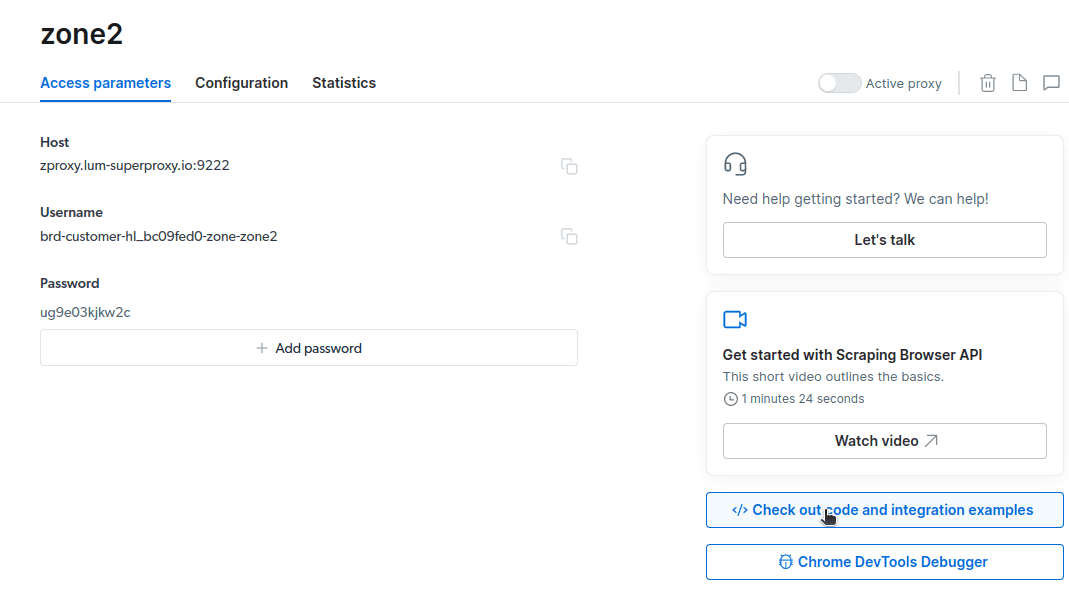
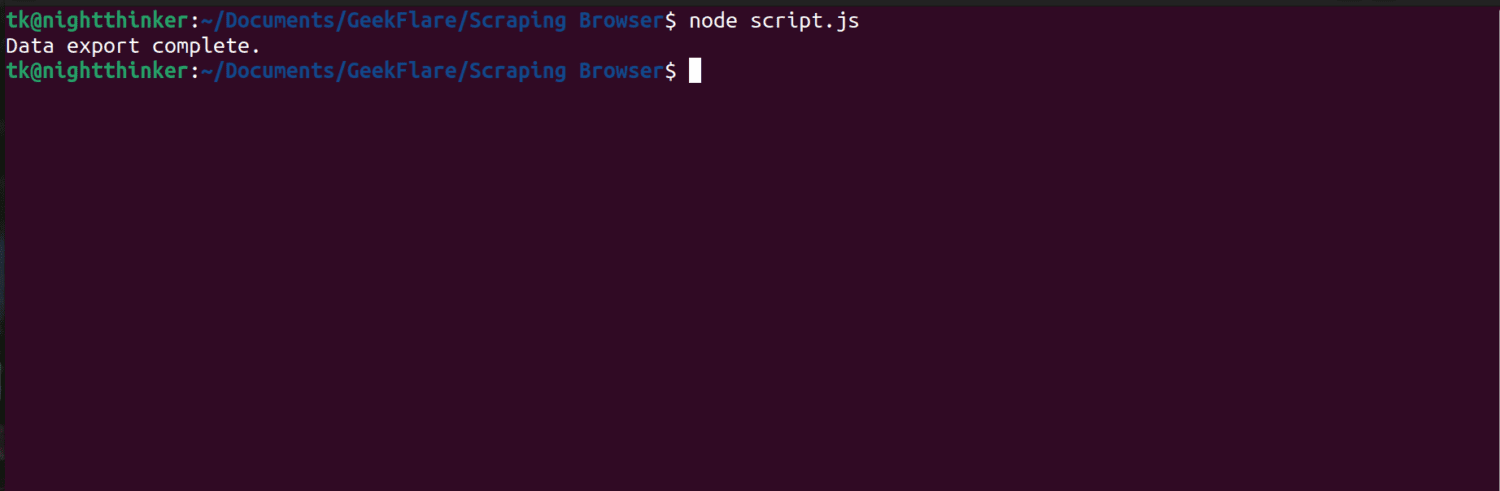
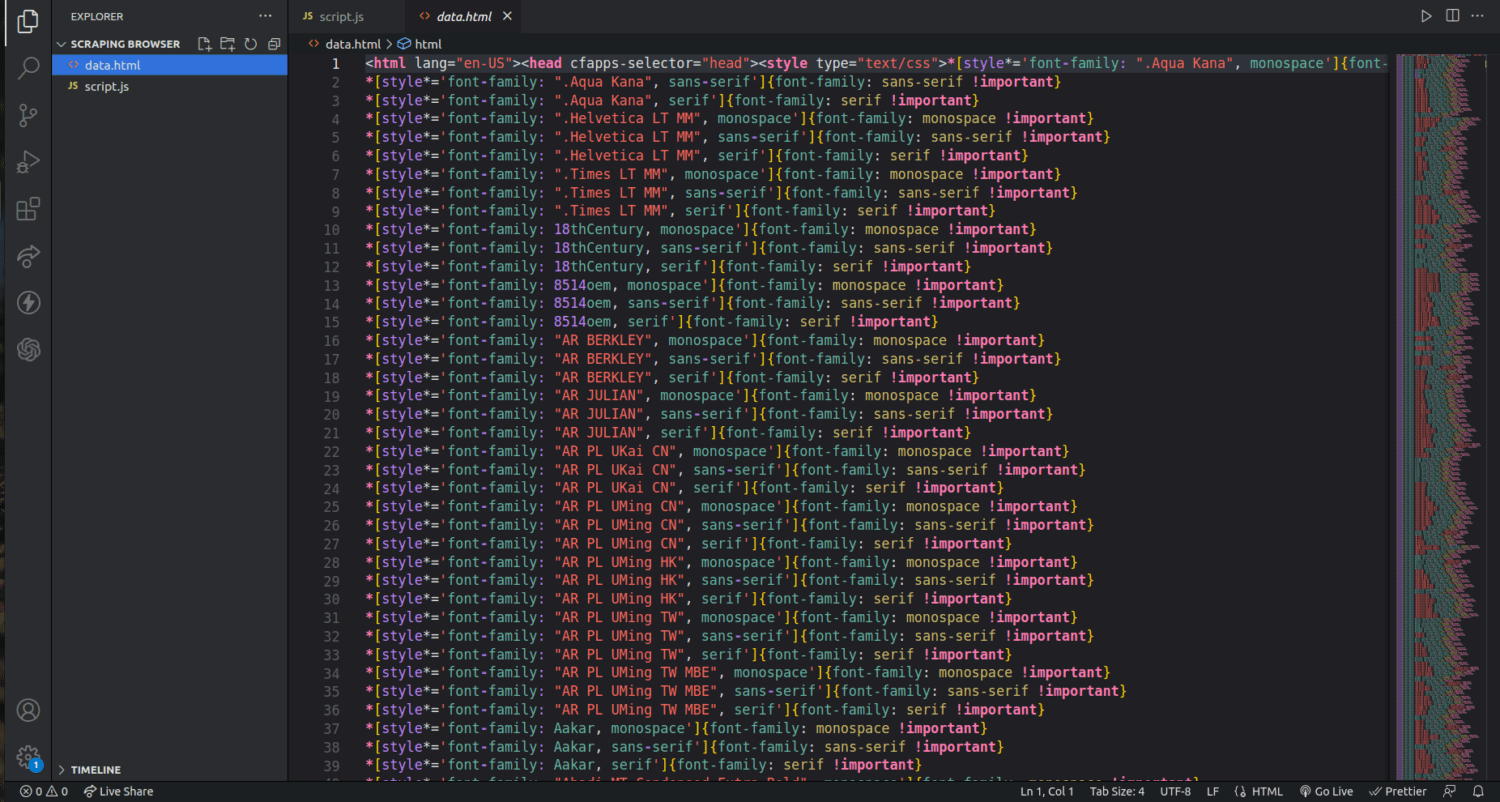
Acum aveți tot ce aveți nevoie pentru a extrage date de pe un site web. Vom folosi site-ul nostru web, tipstrick.ro.com, pentru a demonstra cum funcționează Scraping Browser. Pentru această demonstrație, vom folosi node.js. Puteți urma dacă aveți instalat node.js.
Urmați acești pași;
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="USERNAME:PASSWORD";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
Îmi voi schimba codul de pe linia 10 pentru a fi după cum urmează;