

Deepfake-urile video înseamnă că nu poți avea încredere în tot ceea ce vezi. Acum, deepfakes audio ar putea însemna că nu mai poți avea încredere în urechile tale. Era chiar ăla președintele care declara război Canadei? Este într-adevăr tatăl tău la telefon care îi cere parola de e-mail?
Adăugați o altă îngrijorare existențială la lista cu privire la modul în care propriul nostru orgoliu ne-ar putea distruge inevitabil. În timpul erei Reagan, singurele riscuri tehnologice reale au fost amenințarea războiului nuclear, chimic și biologic.
În anii următori, am avut ocazia să fim obsedați de substanța grey a nanotehnologiei și de pandemiile globale. Acum, avem deepfakes – oameni care își pierd controlul asupra asemănării sau vocii lor.
Cuprins
Ce este un audio Deepfake?
Cei mai mulți dintre noi au văzut un videoclip deepfake, în care algoritmii de deep-learning sunt folosiți pentru a înlocui o persoană cu asemănarea cuiva. Cei mai buni sunt incredibil de realiști, iar acum este rândul audio. Un deepfake audio este atunci când o voce „clonată” care nu poate fi distinsă de cea a persoanei reale este folosită pentru a produce sunet sintetic.
„Este ca Photoshop pentru voce”, a spus Zohaib Ahmed, CEO al Seamănă cu AI, despre tehnologia de clonare a vocii a companiei sale.
Cu toate acestea, lucrările proaste Photoshop sunt ușor dezmințite. O firmă de securitate cu care am vorbit a spus că oamenii, de obicei, ghicesc doar dacă un deepfake audio este real sau fals cu o precizie de aproximativ 57 la sută – nu este mai bun decât o monedă.
În plus, deoarece atât de multe înregistrări vocale sunt de apeluri telefonice de calitate scăzută (sau înregistrate în locații zgomotoase), deepfake-urile audio pot fi făcute și mai imposibil de distins. Cu cât calitatea sunetului este mai proastă, cu atât este mai greu să captezi acele semne revelatoare că o voce nu este reală.
Dar de ce ar avea cineva nevoie de un Photoshop pentru voci, oricum?
Cazul convingător pentru sunetul sintetic
Există de fapt o cerere enormă pentru sunet sintetic. Potrivit lui Ahmed, „Rentabilitatea investiției este foarte imediată”.
Acest lucru este valabil mai ales când vine vorba de jocuri. În trecut, vorbirea era singura componentă a unui joc care era imposibil de creat la cerere. Chiar și în titlurile interactive cu scene de calitate cinematografică redate în timp real, interacțiunile verbale cu personajele care nu joacă sunt întotdeauna esențial statice.
Acum, însă, tehnologia a ajuns din urmă. Studiourile au potențialul de a clona vocea unui actor și de a folosi motoare text-to-speech, astfel încât personajele să poată spune orice în timp real.
Există, de asemenea, utilizări mai tradiționale în reclamă și asistență tehnologică și pentru clienți. Aici, o voce care sună autentic uman și care răspunde personal și contextual fără aport uman este ceea ce este important.
Companiile de clonare a vocii sunt, de asemenea, încântate de aplicațiile medicale. Desigur, înlocuirea vocii nu este o noutate în medicină — Stephen Hawking a folosit faimosul o voce sintetizată robot după ce și-a pierdut-o pe a sa în 1985. Cu toate acestea, clonarea vocii modernă promite ceva și mai bun.
În 2008, compania de voce sintetică, CereProc, a spus criticul de film Roger Ebert, vocea lui înapoi după ce cancerul i-a luat-o. CereProc a publicat o pagină web care permitea oamenilor să tasteze mesaje care urmau să fie apoi rostite în vocea fostului președinte George Bush.
„Ebert a văzut asta și s-a gândit: „Ei bine, dacă ar putea copia vocea lui Bush, ar trebui să o poată copia pe a mea”, a spus Matthew Aylett, directorul științific al CereProc. Ebert a cerut apoi companiei să creeze o voce de înlocuire, ceea ce a făcut prin procesarea unei biblioteci mari de înregistrări vocale.
„A fost una dintre primele când cineva a făcut asta și a fost un real succes”, a spus Aylett.
În ultimii ani, o serie de companii (inclusiv CereProc) au colaborat cu Asociația ALS pe Proiect Revoice pentru a oferi voci sintetice celor care suferă de SLA.

Cum funcționează sunetul sintetic
Clonarea vocii are un moment în acest moment, iar o mulțime de companii dezvoltă instrumente. Seamănă cu AI și Descriere aveți demonstrații online pe care oricine le poate încerca gratuit. Înregistrați doar frazele care apar pe ecran și, în doar câteva minute, este creat un model al vocii tale.
Puteți mulțumi AI – în special algoritmilor de învățare profundă – pentru că sunt capabili să potriviți vorbirea înregistrată cu textul pentru a înțelege fonemele componente care alcătuiesc vocea dumneavoastră. Apoi folosește blocurile lingvistice rezultate pentru a aproxima cuvintele pe care nu le-ai auzit rostiți.
Tehnologia de bază există de ceva vreme, dar, după cum a subliniat Aylett, a necesitat ceva ajutor.
„Copiarea vocii a fost un pic ca a face patiserie”, a spus el. „A fost destul de greu de făcut și au existat diverse moduri în care trebuia să-l modifici manual pentru a-l face să funcționeze.”
Dezvoltatorii aveau nevoie de cantități enorme de date vocale înregistrate pentru a obține rezultate acceptabile. Apoi, acum câțiva ani, s-au deschis porțile. Cercetările în domeniul vederii computerizate s-au dovedit a fi critice. Oamenii de știință au dezvoltat rețele generative adverse (GAN), care ar putea, pentru prima dată, să extrapoleze și să facă predicții pe baza datelor existente.
„În loc ca un computer să vadă o imagine a unui cal și să spună „acesta este un cal”, modelul meu ar putea acum să transforme un cal într-o zebră”, a spus Aylett. „Așadar, explozia în sinteza vorbirii se datorează acum muncii academice din viziunea computerizată.”
Una dintre cele mai mari inovații în clonarea vocii a fost reducerea generală a cantității de date brute necesare pentru a crea o voce. În trecut, sistemele aveau nevoie de zeci sau chiar sute de ore de sunet. Acum, însă, voci competente pot fi generate din doar câteva minute de conținut.
Frica existențială de a nu avea încredere în nimic
Această tehnologie, împreună cu energia nucleară, nanotehnologia, imprimarea 3D și CRISPR, este în același timp palpitant și terifiant. La urma urmei, au existat deja cazuri în știri de oameni păcăliți de clonele vocii. În 2019, o companie din Marea Britanie a susținut că a fost păcălit de un deepfake audio apel telefonic pentru a transfera bani către criminali.
Nici nu trebuie să mergeți departe pentru a găsi falsuri audio surprinzător de convingătoare. Canalul canalului YouTube Sinteză vocală prezintă oameni cunoscuți care spun lucruri pe care nu le-au spus niciodată, cum ar fi George W. Bush citind „In Da Club” de 50 Cent. Este pe loc.
În altă parte pe YouTube, puteți auzi o turmă de foști președinți, inclusiv Obama, Clinton și Reagan, rapând NWA. Muzica și sunetele de fundal ajută la ascunderea unora dintre erorile robotice evidente, dar chiar și în această stare imperfectă, potențialul este evident.
Am experimentat cu instrumentele pornite Seamănă cu AI și Descriere și a creat o clonă de voce. Descript folosește un motor de clonare a vocii care a fost inițial numit Lyrebird și a fost deosebit de impresionant. Am fost șocați de calitate. Să-ți auzi propria voce spunând lucruri pe care știi că nu le-ai spus niciodată este deranjant.
Cu siguranță există o calitate robotică a discursului, dar la o ascultare obișnuită, majoritatea oamenilor nu ar avea niciun motiv să creadă că este un fals.
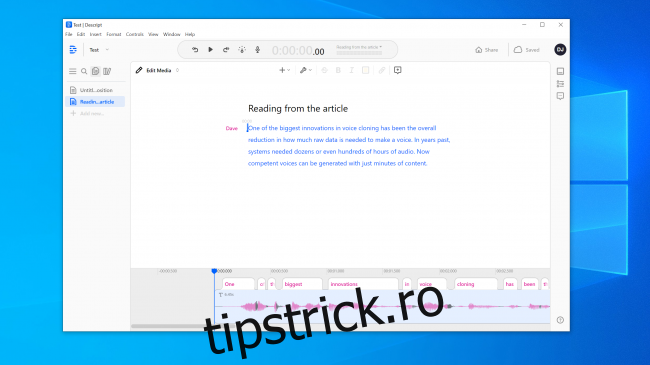
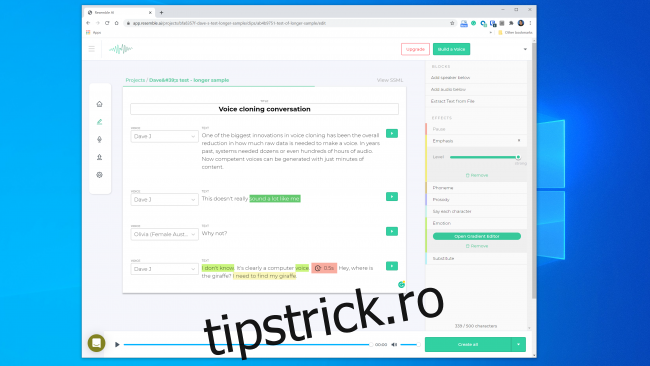
Aveam speranțe și mai mari pentru Resemble AI. Vă oferă instrumentele pentru a crea o conversație cu mai multe voci și pentru a varia expresivitatea, emoția și ritmul dialogului. Cu toate acestea, nu credeam că modelul de voce surprinde calitățile esențiale ale vocii pe care am folosit-o. De fapt, era puțin probabil să păcălească pe cineva.
Un reprezentant de Resemble AI ne-a spus „cei mai mulți oameni sunt uimiți de rezultate dacă o fac corect”. Am construit un model de voce de două ori cu rezultate similare. Deci, evident, nu este întotdeauna ușor să faci o clonă de voce pe care o poți folosi pentru a realiza un furt digital.
Chiar și așa, fondatorul Lyrebird (care face acum parte din Descript), Kundan Kumar, consideră că am depășit deja acest prag.
„Pentru un procent mic de cazuri, este deja acolo”, a spus Kumar. „Dacă folosesc sunetul sintetic pentru a schimba câteva cuvinte într-un discurs, este deja atât de bine încât îți va fi greu să știi ce s-a schimbat.”
De asemenea, putem presupune că această tehnologie se va îmbunătăți cu timpul. Sistemele vor avea nevoie de mai puțin audio pentru a crea un model, iar procesoarele mai rapide vor putea construi modelul în timp real. AI mai inteligentă va învăța cum să adauge o cadență umană mai convingătoare și să pună accentul pe vorbire fără a avea un exemplu din care să lucreze.
Ceea ce înseamnă că s-ar putea să ne apropiem de disponibilitatea pe scară largă a clonării vocii fără efort.
Etica cutiei Pandorei
Majoritatea companiilor care lucrează în acest spațiu par gata să gestioneze tehnologia într-un mod sigur și responsabil. Semănă cu AI, de exemplu, are o întreagă secțiune „Etică” pe site-ul său, iar următorul fragment este încurajator:
„Colaborăm cu companii printr-un proces riguros pentru a ne asigura că vocea pe care o clonează este utilizabilă de către acestea și că avem acordurile adecvate cu actorii vocali.”
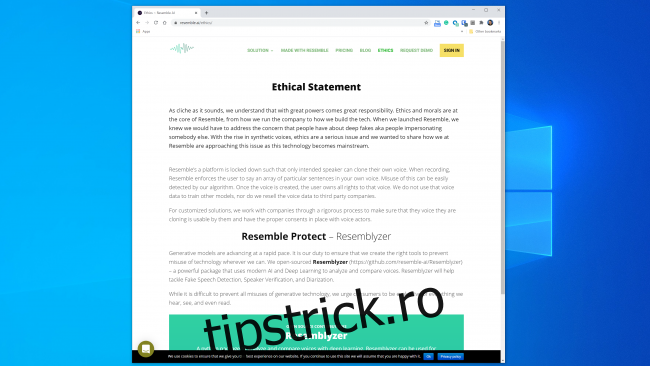
De asemenea, Kumar a spus că Lyrebird a fost îngrijorat de utilizarea abuzivă încă de la început. De aceea, acum, ca parte a Descript, le permite oamenilor doar să-și cloneze propria voce. De fapt, atât Resemble, cât și Descript necesită ca oamenii să-și înregistreze mostrele în direct pentru a preveni clonarea neconsensuală a vocii.
Este încurajator faptul că principalii jucători comerciali au impus niște linii directoare etice. Cu toate acestea, este important să ne amintim că aceste companii nu sunt paznicii acestei tehnologii. Există deja o serie de instrumente open-source deja în sălbăticie, pentru care nu există reguli. Potrivit lui Henry Ajder, șeful departamentului de informații despre amenințări la Deeptrace, de asemenea, nu aveți nevoie de cunoștințe avansate de codare pentru a o folosi greșit.
„O mare parte din progresul în spațiu a venit prin muncă în colaborare în locuri precum GitHub, folosind implementări open-source ale lucrărilor academice publicate anterior”, a spus Ajder. „Poate fi folosit de oricine are competențe moderate în codificare.”
Profesioniștii în securitate au mai văzut toate acestea înainte
Criminalii au încercat să fure bani prin telefon cu mult înainte ca clonarea vocii să fie posibilă, iar experții în securitate au fost întotdeauna de garda pentru a detecta și a preveni acest lucru. Companie de securitate Pindrop încearcă să oprească frauda bancară verificând dacă un apelant este cine pretinde că este din audio. Numai în 2019, Pindrop susține că a analizat 1,2 miliarde de interacțiuni vocale și a prevenit aproximativ 470 de milioane de dolari în tentative de fraudă.
Înainte de clonarea vocii, escrocii au încercat o serie de alte tehnici. Cel mai simplu a fost să sunați din altă parte cu informații personale despre marcă.
„Semnătura noastră acustică ne permite să stabilim că un apel vine de fapt de la un telefon Skype din Nigeria, datorită caracteristicilor sunetului”, a spus CEO-ul Pindrop, Vijay Balasubramaniyan. „Atunci, putem compara faptul că știind că clientul folosește un telefon AT&T în Atlanta.”
Unii criminali și-au făcut carieră folosind sunete de fundal pentru a-i arunca pe reprezentanții bancar.
„Există un fraudator pe care l-am numit Chicken Man, care avea întotdeauna cocoși în fundal”, a spus Balasubramaniyan. „Și există o doamnă care a folosit un copil care plângea în fundal pentru a-i convinge în esență pe agenții centrului de apel că „hei, trec printr-o perioadă grea” pentru a obține simpatie.”
Și apoi sunt criminalii bărbați care merg după conturile bancare ale femeilor.
„Ei folosesc tehnologia pentru a-și crește frecvența vocii, pentru a suna mai feminin”, a explicat Balasubramaniyan. Acestea pot avea succes, dar „ocazional, software-ul se încurcă și sună ca Alvin and the Chipmunks”.
Desigur, clonarea vocii este doar cea mai recentă dezvoltare din acest război în continuă escaladare. Firmele de securitate au prins deja fraudători care foloseau sunet sintetic în cel puțin un atac de pescuit sub apă.
„Cu ținta potrivită, plata poate fi masivă”, a spus Balasubramaniyan. „Așadar, este logic să dedici timpul pentru a crea o voce sintetizată a individului potrivit.”
Poate cineva să spună dacă o voce este falsă?

Când vine vorba de a recunoaște dacă o voce a fost falsificată, există atât vești bune, cât și vești rele. Rău este că clonele de voce sunt din ce în ce mai bune în fiecare zi. Sistemele de învățare profundă devin mai inteligente și fac voci mai autentice, care necesită mai puțin audio pentru a crea.
După cum puteți vedea din acest clip de Președintele Obama îi spune lui MC Ren să ia acțiunea, am ajuns deja la punctul în care un model de voce de înaltă fidelitate, construit cu grijă, poate suna destul de convingător pentru urechea umană.
Cu cât un clip audio este mai lung, cu atât este mai probabil să observați că ceva nu este în regulă. Pentru clipuri mai scurte, totuși, este posibil să nu observați că este sintetic, mai ales dacă nu aveți niciun motiv să puneți la îndoială legitimitatea acestuia.
Cu cât calitatea sunetului este mai clară, cu atât este mai ușor să observați semnele unui deepfake audio. Dacă cineva vorbește direct într-un microfon de calitate studio, vei putea asculta cu atenție. Dar o înregistrare de proastă calitate a unui apel telefonic sau o conversație surprinsă pe un dispozitiv portabil într-o parcare zgomotoasă va fi mult mai greu de evaluat.
Vestea bună este că, chiar dacă oamenii au dificultăți în a separa realul de fals, computerele nu au aceleași limitări. Din fericire, instrumentele de verificare vocală există deja. Pindrop are unul care pune sistemele de învățare profundă unele cu altele. Le folosește pe ambele pentru a descoperi dacă o probă audio este persoana care ar trebui să fie. Cu toate acestea, analizează și dacă un om poate scoate chiar toate sunetele din eșantion.
În funcție de calitatea sunetului, fiecare secundă de vorbire conține între 8.000-50.000 de mostre de date care pot fi analizate.
„Lucrurile pe care le căutăm de obicei sunt constrângeri ale vorbirii din cauza evoluției umane”, a explicat Balasubramaniyan.
De exemplu, două sunete vocale au o separare minimă posibilă unul de celălalt. Acest lucru se datorează faptului că fizic nu este posibil să le spui mai repede din cauza vitezei cu care mușchii din gură și corzile vocale se pot reconfigura.
„Când ne uităm la sunetul sintetizat”, a spus Balasubramaniyan, „uneori vedem lucruri și spunem: „Acesta nu ar fi putut niciodată să fie generat de un om, deoarece singura persoană care ar fi putut să genereze acest lucru trebuie să aibă un gât lung de două metri”. ”
Există, de asemenea, o clasă de sunet numită „fricative”. Ele se formează atunci când aerul trece printr-o constricție îngustă în gât atunci când pronunți litere precum f, s, v și z. Fricativele sunt deosebit de greu de stăpânit de sistemele de învățare profundă, deoarece software-ul are probleme în a le diferenția de zgomot.
Deci, cel puțin deocamdată, software-ul de clonare a vocii este împiedicat de faptul că oamenii sunt pungi de carne care curg aer prin găurile din