

Dacă ați învățat câteva limbaje de programare pentru computer, s-ar putea să fi auzit termenul, parsing text. Acesta este folosit pentru a simplifica valorile complexe ale datelor din fișier. Articolul vă ajută să știți cum să analizați textul folosind limba. În plus, dacă v-ați confruntat cu o eroare în analiza textului x, veți ști cum să remediați eroarea de analizare din articol.

Cuprins
Cum să analizați textul
În acest articol, am arătat un ghid complet pentru analizarea textului prin diferite moduri și, de asemenea, am prezentat pe scurt o introducere în analiza textului.
Ce este Parsing Text?
Înainte de a explora conceptele de analiză a textului folosind orice cod. Este important să cunoașteți elementele de bază ale limbajului și codificarea.
NLP sau procesarea limbajului natural
Pentru a analiza textul, se utilizează procesarea limbajului natural sau NLP, care este un subdomeniu al domeniului Inteligenței artificiale. Limbajul Python, care este una dintre limbile care aparțin categoriei, este folosit pentru a analiza textul.
Codurile NLP permit computerelor să înțeleagă și să proceseze limbaje umane pentru a le face potrivite pentru diverse aplicații. Pentru a aplica tehnici ML sau Machine Learning la limbă, datele text nestructurate trebuie convertite în date tabelare structurate. Pentru finalizarea activității de analiză, limbajul Python este folosit pentru a modifica codurile programului.
Ce este Parsing Text?
Analizarea textului înseamnă pur și simplu convertirea datelor dintr-un format în alt format. Formatul în care este salvat fișierul va fi analizat sau convertit într-un fișier într-un format diferit pentru a permite utilizatorului să-l folosească în diferite aplicații.
- Cu alte cuvinte, procesul înseamnă analiza șirului sau a unui text și convertirea în componente logice prin modificarea formatului fișierului.
- Unele reguli ale limbajului Python sunt utilizate pentru a finaliza această sarcină comună de programare. În timpul analizării textului, seria dată de text este împărțită în componente mai mici.
Care sunt motivele pentru a analiza textul?
Motivele pentru care textul trebuie analizat sunt prezentate în această secțiune și este o cunoaștere prealabilă înainte de a ști cum să analizați textul.
- Toate datele computerizate nu vor fi în același format și pot diferi în funcție de diferite aplicații.
- Formatele de date variază pentru diferite aplicații și un cod incompatibil ar duce la această eroare.
- Nu există un program de calculator universal individual pentru selectarea datelor tuturor formatelor de date.
Metoda 1: Prin clasa DataFrame
Clasa DataFrame a limbajului Python are toate funcțiile necesare pentru a analiza textul. Această bibliotecă încorporată găzduiește codurile necesare pentru a analiza datele de orice format într-un alt format.
Scurtă introducere a clasei DataFrame
DataFrame Class este o structură de date bogată în caracteristici, care este utilizată ca instrument de analiză a datelor. Acesta este un instrument puternic de analiză a datelor care poate fi utilizat pentru a analiza datele cu un efort minim.
- Codul este citit în Pandas DataFrame pentru a efectua analiza în limbajul Python.
- Clasa vine cu numeroase pachete furnizate de panda, care sunt folosite de analiștii de date Python.
- Caracteristica acestei clase este o abstractizare, un cod în care funcționalitatea internă a funcției este ascunsă utilizatorilor, a bibliotecii NumPy. Biblioteca NumPy este o bibliotecă Python care cuprinde comenzile și funcțiile pentru lucrul cu matrice.
- Clasa DataFrame poate fi folosită pentru a reda o matrice bidimensională cu mai mulți indici de rânduri și coloane. Acești indici ajută la stocarea datelor multidimensionale și, prin urmare, se numesc MultiIndex. Acestea trebuie modificate pentru a ști cum să remediați eroarea de analiză.
Pandas din limbajul Python ajută la efectuarea operațiunilor SQL sau în stilul bazei de date cu cea mai mare perfecțiune pentru a evita erorile în analiza textului x. De asemenea, conține câteva instrumente IO care ajută la analiza fișierelor CSV, MS Excel, JSON, HDF5 și alte formate de date.
Procesul de analizare a textului folosind clasa DataFrame
Pentru a ști cum să analizați textul, puteți utiliza procesul standard folosind clasa DataFrame dată în această secțiune.
- Descifrați formatul datelor de intrare.
- Decideți datele de ieșire ale datelor, cum ar fi CSV sau Valoare separată prin virgulă.
- Scrieți pe cod un tip de date primitiv, cum ar fi listă sau dict.
Notă: Scrierea codului pe un DataFrame gol poate fi plictisitoare și complexă. Pandas permit crearea datelor din clasa DataFrame din aceste tipuri de date. Prin urmare, datele din tipul de date primitiv pot fi analizate cu ușurință în formatul de date necesar.
- Analizați datele folosind instrumentul de analiză a datelor, Pandas DataFrame și imprimați rezultatul.
Opțiunea I: Format standard
Metoda standard de a formata orice fișier cu un anumit format de date, cum ar fi CSV, este explicată aici.
- Salvați fișierul cu valorile datelor local pe computer. De exemplu, puteți numi fișierul data.txt.
- Importați fișierul în panda cu un nume specific și importați datele într-o altă variabilă. De exemplu, panda limbii sunt importate în numele pd din codul dat.
- Importul ar trebui să aibă un cod complet cu detaliile numelui fișierului de intrare, funcției și formatului fișierului de intrare.
Notă: Aici, variabila numită res este folosită pentru a efectua funcția de citire a datelor din fișierul data.txt folosind panda importate în pd. Formatul de date al textului introdus este specificat în format CSV.
- Apelați tipul de fișier numit și analizați textul analizat pe rezultatul tipărit. De exemplu, comanda res după executarea liniei de comandă va ajuta la tipărirea textului analizat.
Un exemplu de cod pentru procesul explicat mai sus este dat mai jos și vă va ajuta să înțelegeți cum să analizați textul.
import pandas as pd res = pd.read_csv(‘data.txt’) res
În acest caz, dacă introduceți valorile datelor în fișierul data.txt, cum ar fi [1,2,3]ar fi analizat și afișat ca 1 2 3.
Opțiunea II: Metoda șirurilor
Dacă textul dat codului conține doar șiruri de caractere sau caractere alfa, caracterele speciale din șir, cum ar fi virgulele, spațiul etc., pot fi folosite pentru a separa și analiza textul. Procesul este similar cu operațiile obișnuite cu șiruri interne. Pentru a afla cum să remediați eroarea de analizare, trebuie să urmați procesul de analizare a textului folosind această opțiune este explicată mai jos.
- Datele sunt extrase din șir și toate caracterele speciale care separă textul sunt notate.
De exemplu, în codul de mai jos, sunt identificate caracterele speciale din șirul my_string, care sunt „,” și „:”. Acest proces trebuie făcut cu atenție pentru a evita eroarea în analiza textului x.
- Textul din șir este împărțit individual în funcție de valorile și poziția caracterelor speciale.
De exemplu, șirul este împărțit în valori de date text pe baza caracterelor speciale identificate folosind comanda split.
- Valorile de date ale șirului sunt tipărite singure ca text analizat. Aici, instrucțiunea print este folosită pentru a tipări valoarea datelor analizate a textului.
Exemplul de cod pentru procesul explicat mai sus este prezentat mai jos.
my_string = ‘Names: Tech, computer’
sfinal = [name.strip() for name in my_string.split(‘:’)[1].split(‘,’)]
print(“Names: {}”.format(sfinal))
În acest caz, rezultatul șirului analizat va fi afișat așa cum se arată mai jos.
Names: [‘Tech’, ‘computer’]
Pentru a obține o claritate mai bună și pentru a ști cum să analizați textul în timp ce utilizați textul șir, se utilizează o buclă for, iar codul este modificat după cum urmează.
my_string = ‘Names: Tech, computer’
s1 = my_string.split(‘:’)
s2 = s1[1]
s3 = s2.split(‘,’)
s4 = [name.strip() for name in s3]
for idx, item in enumerate([s1, s2, s3, s4]):
print(“Step {}: {}”.format(idx, item))
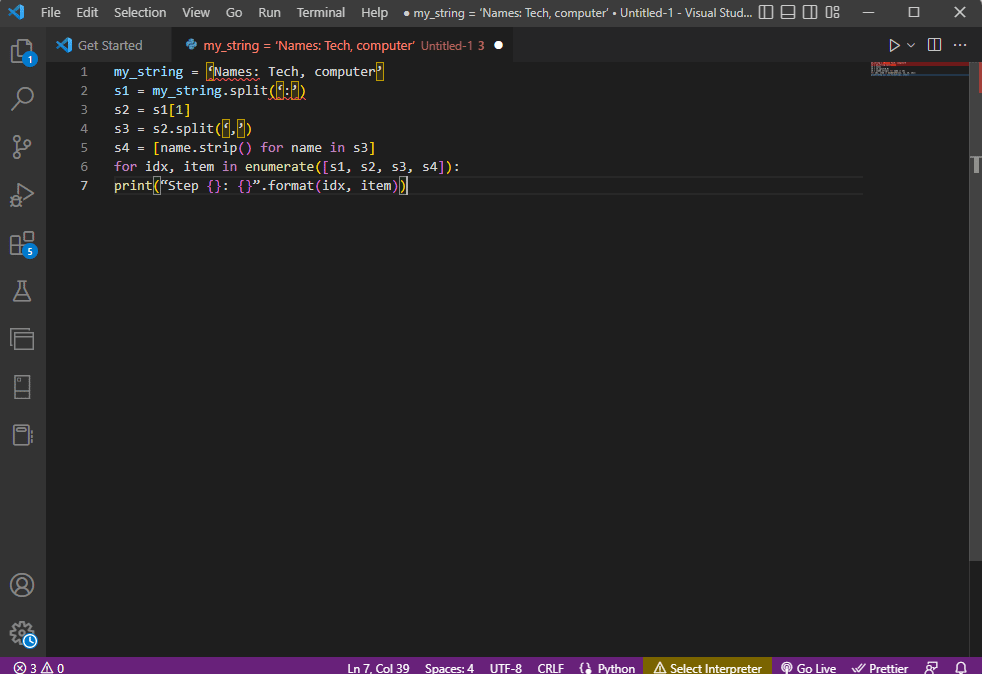
Rezultatul textului analizat pentru fiecare dintre acești pași este afișat după cum este prezentat mai jos. Puteți observa că, la Pasul 0, șirul este separat pe baza caracterului special : iar valorile datelor de text sunt separate în funcție de caracter în pașii ulterioare.
Step 0: [‘Names’, ‘Tech, computer’] Step 1: Tech, computer Step 2: [‘ Tech’, ‘ computer’] Step 3: [‘Tech’, ‘computer’]
Opțiunea III: Analizarea fișierului complex
În majoritatea cazurilor, datele fișierului care trebuie analizate conțin diferite tipuri de date și valori ale datelor. În acest caz, ar putea fi dificil să analizați fișierul folosind metodele explicate mai devreme.
Caracteristicile analizării datelor complexe din fișier sunt de a face ca valorile datelor să fie afișate într-un format tabelar.
- Titlul sau metadatele valorilor sunt tipărite în partea de sus a fișierului,
- Variabilele și câmpurile sunt tipărite în rezultat într-o formă tabelară și
- Valorile datelor formează o cheie compusă.
Înainte de a învăța cum să analizați textul în această metodă, este necesar să învățați câteva concepte de bază. Analiza valorilor datelor se face pe baza expresiilor regulate sau Regex.
Modele regex
Pentru a ști cum să remediați eroarea de analiză, trebuie să vă asigurați că modelele regex din expresii sunt corecte. Codul de analizare a valorilor de date ale șirurilor de caractere ar implica modelele Regex comune enumerate mai jos în această secțiune.
-
„d”: se potrivește cu cifra zecimală din șir,
-
„s”: se potrivește cu caracterul de spațiu alb,
-
„w”: se potrivește cu caracterul alfanumeric,
-
„+” sau „*”: efectuează o potrivire lacomă prin potrivirea unuia sau mai multor caractere din șiruri,
-
„a-z”: se potrivește cu grupurile de litere mici din valorile datelor text,
-
„A-Z” sau „a-z”: se potrivește cu grupurile mari și mici ale șirului și
-
„0-9”: se potrivește cu valorile numerice.
Expresii obisnuite
Modulele de expresie regulată sunt o parte majoră a pachetului Pandas în limbajul Python și o re greșită poate duce la o eroare în analiza textului x. Este un limbaj mic încorporat în Python pentru a găsi modelul de șir în expresie. Expresiile regulate sau Regex sunt șiruri de caractere cu sintaxă specială. Acesta permite utilizatorului să potrivească modele din alte șiruri pe baza valorilor din șiruri.
Regex este creat pe baza tipului de date și a cerinței expresiei din șir, cum ar fi „String = (.*)n. Regex este folosit înaintea modelului în fiecare expresie. Simbolurile folosite în expresiile regulate sunt enumerate mai jos și vă vor ajuta să știți cum să analizați textul.
-
. : pentru a prelua orice caracter din date,
-
*: utilizați zero sau mai multe date din expresia anterioară,
-
(.*): pentru a grupa o parte a expresiei regulate în paranteze,
-
n: Creați un nou caracter de linie la sfârșitul liniei în cod,
-
d: creați o valoare integrală scurtă în intervalul de la 0 la 9,
-
+ : folosește una sau mai multe date din expresia anterioară și
-
| : creați o declarație logică; folosit pentru sau expresii.
RegexObjects
RegexObject este o valoare returnată pentru funcția de compilare și este folosită pentru a returna un MatchObject dacă expresia se potrivește cu valoarea potrivirii.
1. MatchObject
Deoarece valoarea booleană a MatchObject este întotdeauna True, puteți utiliza o instrucțiune if pentru a identifica potrivirile pozitive din obiect. În cazul utilizării instrucțiunii if, grupul la care face referire indexul este folosit pentru a afla potrivirea obiectului din expresie.
-
group() returnează unul sau mai multe subgrupuri de potrivire,
-
group(0) returnează întregul meci,
-
group(1) returnează primul subgrup între paranteze și
- În timp ce ne referim la mai multe grupuri, ar trebui să folosim o extensie specifică Python. Această extensie este utilizată pentru a specifica numele grupului în care trebuie găsită potrivirea. Extensia specifică este furnizată în cadrul grupului între paranteze. De exemplu, expresia, (?P
regex1) s-ar referi la grupul specific cu numele group1 și va verifica potrivirea în expresia regulată, regex1. Pentru a afla cum să remediați eroarea de analiză, trebuie să verificați dacă grupul este indicat corect.
2. Metode de MatchObject
În timp ce găsiți cum să analizați textul, este important să știți că MatchObject are două metode de bază, așa cum sunt enumerate mai jos. Dacă MatchObject este găsit în expresia specificată, va returna instanța sa, în caz contrar, va returna Nimic.
- Metoda match(string) este folosită pentru a găsi potrivirile șirului la începutul expresiei regulate și
- Metoda search(string) este folosită pentru a scana șirul pentru a găsi locația unei potriviri în expresia regulată.
Funcții de expresie regulată
Funcțiile Regex sunt linii de cod care sunt utilizate pentru a îndeplini o anumită funcție, așa cum este specificată de utilizator din setul de valori de date procurat.
Notă: Pentru a scrie funcțiile, sunt folosite șiruri brute pentru expresiile regulate pentru a evita erorile în analiza textului x. Acest lucru se face prin adăugarea indicelui r înaintea fiecărui model din expresie.
Funcțiile comune utilizate în expresii sunt explicate mai jos.
1. re.găsește()
Această funcție returnează toate modelele din șir dacă se găsește o potrivire și returnează o listă goală dacă nu se găsește nicio potrivire. De exemplu, funcția, șir = re.findall(‘[aeiou]’, regex_filename) este folosit pentru a găsi apariția vocalei în numele fișierului.
2. re.split()
Această funcție este folosită pentru a împărți șirul în cazul în care se găsește o potrivire cu un caracter specificat, cum ar fi spațiul. În cazul în care nu se găsește nicio potrivire, returnează un șir gol.
3. re.sub()
Funcția înlocuiește textul potrivit cu conținutul variabilei de înlocuire date. Spre deosebire de alte funcții, dacă nu este găsit niciun model, șirul original este returnat.
4. cercetare ()
Una dintre funcțiile de bază care vă ajută să învățați cum să analizați textul este funcția de căutare. Ajută la căutarea modelului din șir și la returnarea obiectului potrivire. Dacă căutarea eșuează în identificarea potrivirii, nu se returnează nicio valoare.
5. re.compilează(model)
Această funcție este folosită pentru a compila modele de expresii regulate într-un RegexObject, despre care a fost discutat mai devreme.
Alte cerinte
Cerințele enumerate sunt o caracteristică suplimentară utilizată de programatorii avansați în analiza datelor.
- Pentru a vizualiza expresia regulată, se folosește expresia regexper și
- Pentru a testa expresia regulată, se folosește regex101.
Procesul de analizare a textului
Metoda de analizare a textului în această opțiune complexă este descrisă mai jos.
- Cel mai important pas este să înțelegeți formatul de intrare citind conținutul fișierului. De exemplu, funcțiile with open și read() sunt folosite pentru a deschide și a citi conținutul fișierului numit sample. Fișierul eșantion are conținutul din fișierul file.txt; pentru a afla cum să remediați eroarea de analiză, fișierul trebuie citit complet.
- Conținutul fișierului este tipărit pentru a analiza manual datele pentru a afla metadatele valorilor. Aici, funcția print() este folosită pentru a tipări conținutul fișierului eșantion.
- Pachetele de date necesare pentru a analiza textul sunt importate în cod și este dat un nume clasei pentru codificare ulterioară. Aici, expresiile regulate și panda sunt importate.
- Expresiile regulate necesare pentru cod sunt definite în fișier prin includerea modelului regex și a funcției regex. Acest lucru permite obiectului text sau corpus să ia codul pentru analiza datelor.
- Pentru a ști cum să analizați textul, puteți consulta exemplul de cod dat aici. Funcția compile() este folosită pentru a compila șirul din grupul șirnume1 al numelui fișierului. Funcția de verificare a potrivirilor în expresia regex este utilizată de comanda ief_parse_line(line),
- Analizatorul de linie pentru cod este scris folosind def_parse_file(filepath), în care funcția definită verifică toate potrivirile regex din funcția specificată. Aici, metoda regex search() caută cheia rx în numele fișierului și returnează cheia și potrivirea primului regex care se potrivește. Orice problemă cu pasul poate duce la o eroare în analiza textului x.
- Următorul pas este să scrieți un File Parser folosind funcția de file parser, care este def_parse_file(filepath). Este creată o listă goală pentru a colecta datele codului, ca data = []potrivirea este verificată la fiecare linie prin potrivire = _parse_line(line), iar datele exacte ale valorii sunt returnate pe baza tipului de date.
- Pentru a extrage numărul și valoarea pentru tabel, se folosește comanda line.strip().split(‘,’). Comanda row{} este folosită pentru a crea un dicționar cu rândul de date. Comanda data.append(row) este folosită pentru a înțelege datele și a le analiza într-un format tabelar.
Comanda data = pd.DataFrame(data) este folosită pentru a crea un panda DataFrame din valorile dict. Alternativ, puteți utiliza următoarele comenzi în scopul respectiv, așa cum este menționat mai jos.
-
data.set_index([‘string’, ‘integer’]inplace=True) pentru a seta indexul tabelului.
-
data = data.groupby(level=data.index.names).first() pentru a consolida și elimina nans.
-
data = data.apply(pd.to_numeric, errors=’ignore’) pentru a actualiza scorul de la valoarea float la valoarea întreagă.
Ultimul pas pentru a ști cum să analizați textul este să testați analizatorul utilizând instrucțiunea if prin alocarea valorilor unei date variabile și prin imprimarea acesteia folosind comanda print(data).
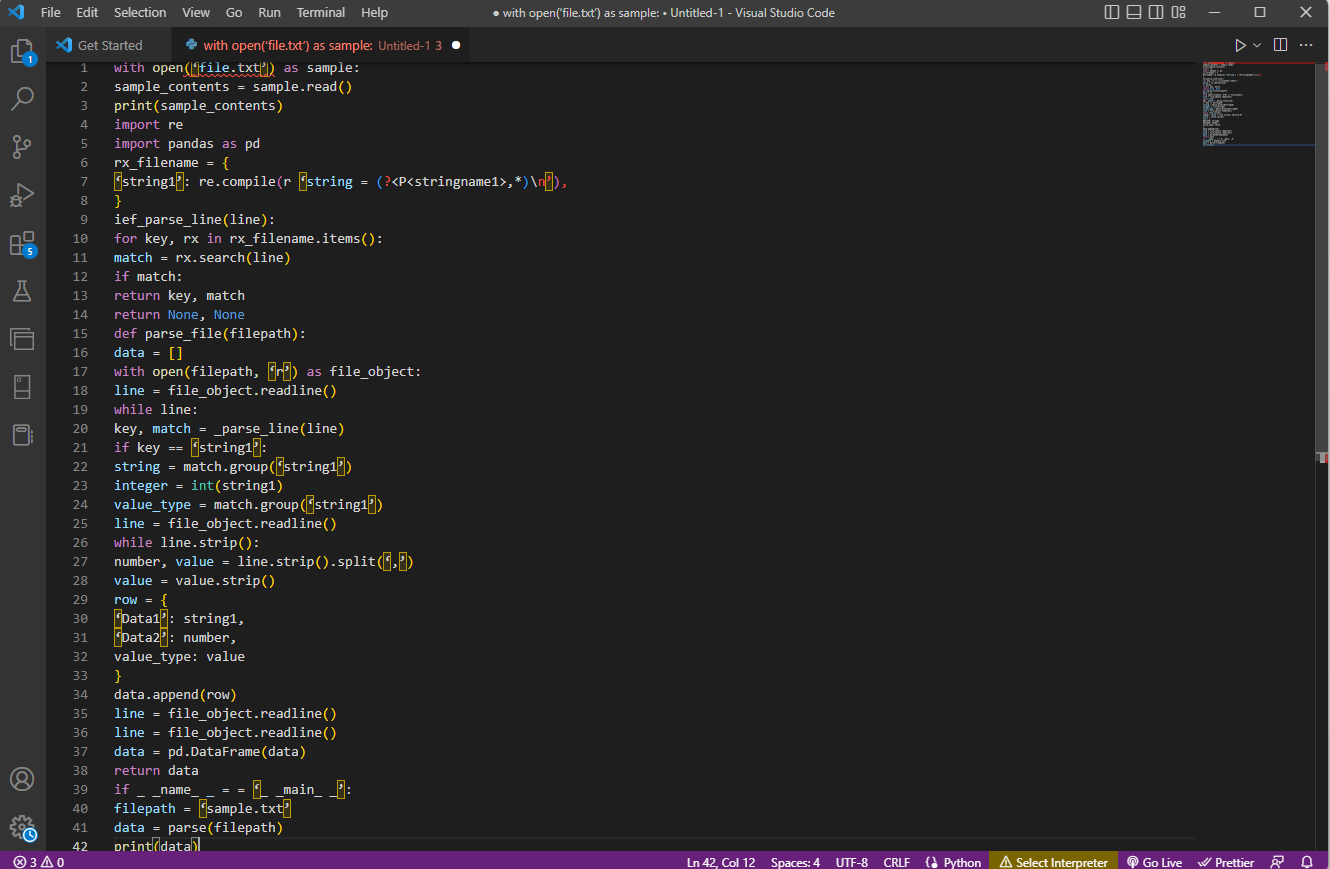
Exemplul de cod pentru explicația de mai sus este dat aici.
with open(‘file.txt’) as sample:
sample_contents = sample.read()
print(sample_contents)
import re
import pandas as pd
rx_filename = {
‘string1’: re.compile(r ‘string = (?<P<stringname1>,*)n’),
}
ief_parse_line(line):
for key, rx in rx_filename.items():
match = rx.search(line)
if match:
return key, match
return None, None
def parse_file(filepath):
data = []
with open(filepath, ‘r’) as file_object:
line = file_object.readline()
while line:
key, match = _parse_line(line)
if key == ‘string1’:
string = match.group(‘string1’)
integer = int(string1)
value_type = match.group(‘string1’)
line = file_object.readline()
while line.strip():
number, value = line.strip().split(‘,’)
value = value.strip()
row = {
‘Data1’: string1,
‘Data2’: number,
value_type: value
}
data.append(row)
line = file_object.readline()
line = file_object.readline()
data = pd.DataFrame(data)
return data
if _ _name_ _ = = ‘_ _main_ _’:
filepath = ‘sample.txt’
data = parse(filepath)
print(data)
Metoda 2: Prin tokenizarea cuvintelor
Procesul de conversie a unui text sau corpus în jetoane sau bucăți mai mici pe baza anumitor reguli se numește Tokenizare. Pentru a afla cum să remediați eroarea de analiză, este important să analizați comenzile de tokenizare a cuvintelor din cod. Similar cu regex, pot fi create reguli proprii în această metodă și ajută la sarcinile de preprocesare a textului, cum ar fi maparea părților de vorbire. De asemenea, activități precum găsirea și potrivirea cuvintelor comune, curățarea textului și pregătirea datelor pentru tehnici avansate de analiză a textului, cum ar fi analiza sentimentelor, sunt efectuate în această metodă. Dacă tokenizarea este necorespunzătoare, poate apărea o eroare în analiza textului x.
Biblioteca Ntlk
Procesul are ajutorul popularei biblioteci de instrumente de limbaj numită nltk, care are un set bogat de funcții pentru efectuarea multor joburi NLP. Acestea pot fi descărcate prin pachetele de instalare Pip sau Pip. Pentru a ști cum să analizați textul, puteți utiliza pachetul de bază al distribuției Anaconda, care include biblioteca în mod implicit.
Forme de tokenizare
Formele comune ale acestei metode sunt tokenizarea cuvintelor și tokenizarea propozițiilor. Datorită simbolului la nivel de cuvânt, primul tipărește un cuvânt o singură dată, în timp ce cel de-al doilea tipărește cuvântul la nivel de propoziție.
Procesul de analizare a textului
- Biblioteca ntlk toolkit este importată, iar formularele de tokenizare sunt importate din bibliotecă.
- Este dat un șir și sunt date comenzile pentru a efectua tokenizarea.
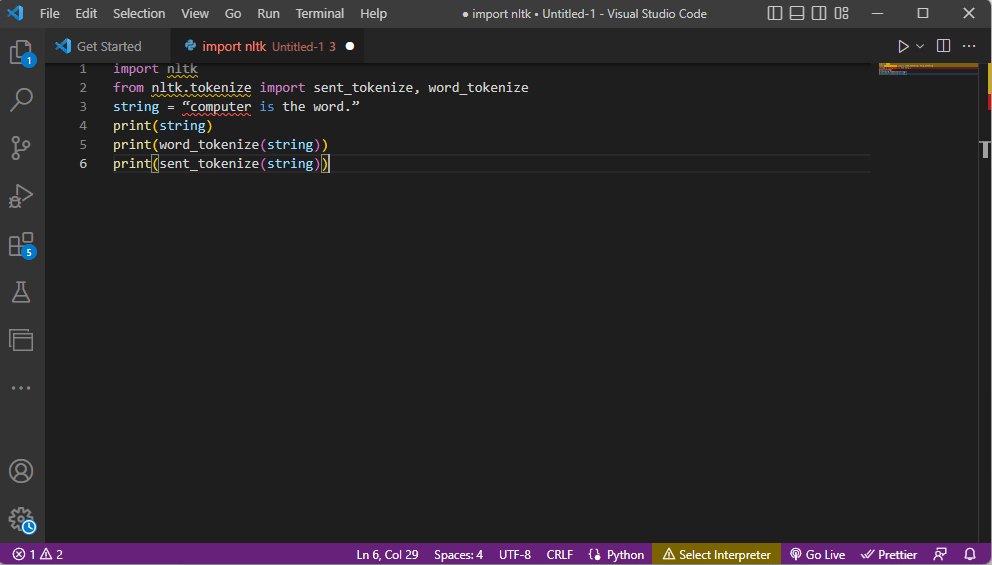
- În timp ce șirul este tipărit, rezultatul ar fi computer este cuvântul.
- În cazul tokenizării cuvântului sau word_tokenize(), fiecare cuvânt din propoziție este imprimat individual în „” și este separat prin virgulă. Ieșirea pentru comandă ar fi „computer”, „este”, „the”, „cuvânt”, „.”
- În cazul tokenizării propoziției sau sent_tokenize(), propozițiile individuale sunt plasate în „” și este permisă repetarea cuvântului. Ieșirea pentru comandă ar fi „calculatorul este cuvântul”.
Codul care explică pașii pentru tokenizare de mai sus este prezentat aici.
import nltk from nltk.tokenize import sent_tokenize, word_tokenize string = “computer is the word.” print(string) print(word_tokenize(string)) print(sent_tokenize(string))
Metoda 3: Prin clasa DocParser
Similar cu clasa DataFrame, clasa DocParser poate fi folosită pentru a analiza textul din cod. Clasa vă permite să apelați funcția de analiză cu calea fișierului.
Procesul de analizare a textului
Pentru a ști cum să analizați text folosind clasa DocParser, urmați instrucțiunile de mai jos.
- Funcția get_format(nume fișier) este utilizată pentru a extrage extensia fișierului, pentru a o returna la o variabilă setată pentru funcție și pentru a o transmite la următoarea funcție. De exemplu, p1 = get_format(filename) ar extrage extensia fișierului filename, o va seta la variabila p1 și o va trece la următoarea funcție.
- O structură logică cu alte funcții este construită folosind instrucțiunile și funcțiile if-elif-else.
- Dacă extensia de fișier este validă și structura este logică, funcția get_parser este utilizată pentru a analiza datele din calea fișierului și a returna obiectul șir către utilizator.
Notă: Pentru a ști cum să remediați eroarea de analiză, această funcție trebuie implementată corect.
- Analiza valorilor datelor se face cu extensia fișierului. Implementarea concretă a clasei, care sunt parse_txt sau parse_docx este folosită pentru a genera obiecte șir din părțile tipului de fișier dat.
- Analiza poate fi efectuată pentru fișiere cu alte extensii care pot fi citite, cum ar fi parse_pdf, parse_html și parse_pptx.
- Valorile datelor și interfața pot fi importate în aplicații cu instrucțiuni de import și pot instanția un obiect DocParser. Acest lucru se poate face prin analizarea fișierelor în limbajul Python, cum ar fi parse_file.py. Această operație trebuie făcută cu atenție pentru a evita eroarea în analiza textului x.
Metoda 4: Prin instrumentul Parse Text
Instrumentul Parse text este folosit pentru a extrage date specifice din variabile și pentru a le mapa cu alte variabile. Acesta este independent de orice alte instrumente utilizate într-o sarcină, iar instrumentul BPA Platform este folosit pentru a consuma și a scoate variabile. Utilizați linkul oferit aici pentru a accesa Instrumentul de analiză a textului online și folosiți răspunsurile date mai devreme despre cum să analizați textul.
Metoda 5: Prin TextFieldParser (Visual Basic)
TextFieldParser a folosit obiecte pentru a analiza și procesa fișiere foarte mari care sunt structurate și delimitate. Lățimea și coloana de text, cum ar fi fișierele jurnal sau informațiile vechi ale bazei de date pot fi utilizate în această metodă. Metoda de analizare este similară cu repetarea codului peste un fișier text și este folosită în principal pentru a extrage câmpuri de text similare cu metodele de manipulare a șirurilor. Acest lucru se face pentru a tokeniza șiruri și câmpuri delimitate de diferite lățimi folosind delimitatorul definit, cum ar fi virgula sau spațiul de tabulație.
Funcții de analizare a textului
Următoarele funcții pot fi folosite pentru a analiza textul în această metodă.
- Pentru a defini un delimitator, se utilizează SetDelimiters. De exemplu, comanda testReader.SetDelimiters (vbTab) este folosită pentru a seta spațiul de tab ca delimitator.
- Pentru a seta o lățime a câmpului la o valoare întreagă pozitivă la o lățime a câmpului fixă a fișierelor text, puteți utiliza comanda testReader.SetFieldWidths (integer).
- Pentru a testa tipul de câmp al textului, puteți utiliza următoarea comandă testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth.
Metode pentru a găsi MatchObject
Există două metode de bază pentru a găsi MatchObject în cod sau textul analizat.
- Prima metodă este de a defini formatul și bucla prin fișier folosind metoda ReadFields. Această metodă ar ajuta la procesarea fiecărei linii a codului.
- Metoda PeekChars este folosită pentru a verifica fiecare câmp individual înainte de a-l citi, pentru a defini mai multe formate și pentru a reacționa.
În oricare dintre cazuri, dacă un câmp nu se potrivește cu formatul specificat în timpul efectuării parsării sau a găsirii modului de analizare a textului, este returnată o excepție MalformedLineException.
Sfat profesionist: Cum să analizați textul prin MS Excel
Ca metodă finală și simplă de a analiza textul, puteți utiliza MS Excel aplicație ca analizator pentru a crea fișiere delimitate de tabulatori și delimitate de virgulă. Acest lucru ar ajuta la verificarea încrucișată cu rezultatul analizat și ar ajuta la găsirea modului de remediere a erorii de analizare.
1. Selectați valorile datelor din fișierul sursă și apăsați împreună tastele Ctrl + C pentru a copia fișierul.
2. Deschideți aplicația Excel folosind bara de căutare din Windows.
3. Faceți clic pe celula A1 și apăsați simultan tastele Ctrl + V pentru a lipi textul copiat.
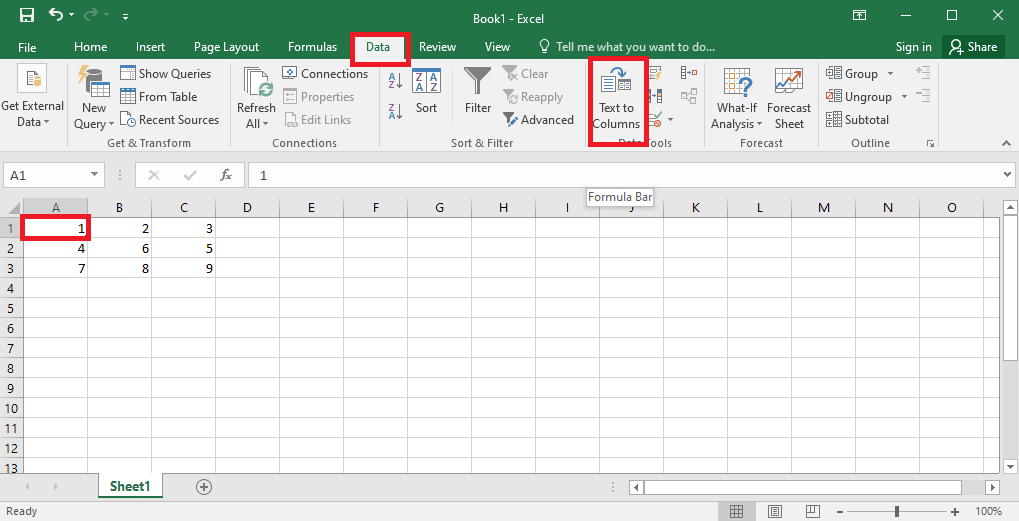
4. Selectați celula A1, navigați la fila Date și faceți clic pe opțiunea Text în coloane din secțiunea Instrumente de date.
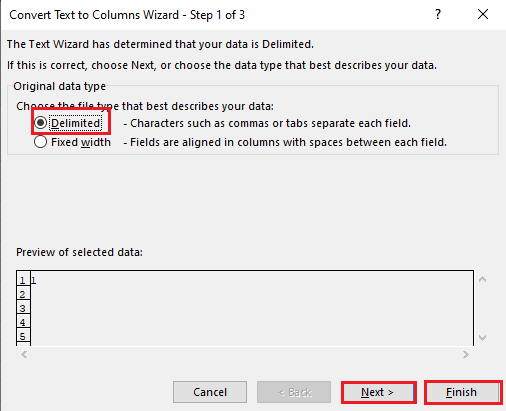
5A. Selectați opțiunea Delimitat dacă este folosită o virgulă sau un spațiu de tabulație ca separator și faceți clic pe butoanele Următorul și Terminare.
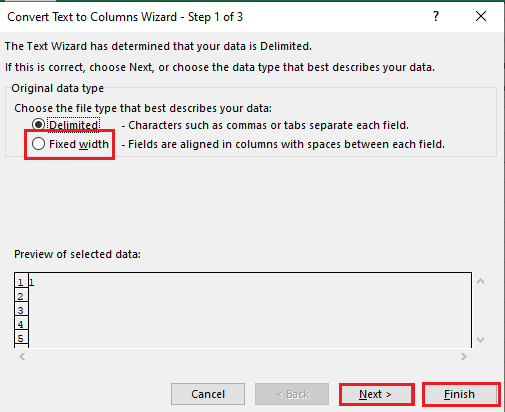
5B. Selectați opțiunea Lățime fixă, atribuiți o valoare pentru separator și faceți clic pe butoanele Următorul și Terminare.
Cum se remediază eroarea de analiză
Eroare la analizarea textului x poate apărea pe dispozitivele Android ca, Eroare de analizare: a apărut o problemă la analizarea pachetului. Acest lucru se întâmplă de obicei atunci când aplicația nu reușește să se instaleze din Magazinul Google Play sau în timp ce rulează o aplicație terță parte.
Textul de eroare x poate apărea dacă lista de vectori de caractere este buclă și alte funcții formează un model liniar pentru calcularea valorilor datelor. Mesajul de eroare este Error in parse(text = x, keep.source = FALSE):
Puteți citi articolul despre cum să remediați eroarea de analiză pe Android pentru a afla cauzele și metodele de remediere a erorii.
În afară de soluțiile din ghid, puteți încerca următoarele remedieri.
- Redescărcarea fișierului .apk sau restaurarea numelui fișierului.
- Restabilirea modificărilor din fișierul Androidmanifest.xml, dacă aveți abilități de programare la nivel de expert.
***
Articolul vă ajută să învățați cum să analizați textul și să învățați cum să remediați eroarea de analizare. Spuneți-ne ce metodă a ajutat la remedierea erorii în analiza textului x și ce metodă de analizare este preferată. Vă rugăm să împărtășiți sugestiile și întrebările dvs. în secțiunea de comentarii de mai jos.