
O matrice de confuzie este un instrument de evaluare a performanței tipului de clasificare a algoritmilor de învățare automată supravegheați.
Cuprins
Ce este o matrice de confuzie?
Noi, oamenii, percepem lucrurile diferit – chiar și adevărul și minciunile. Ceea ce mi se pare o linie lungă de 10 cm, ți se poate părea o linie de 9 cm. Dar valoarea reală poate fi 9, 10 sau altceva. Ceea ce presupunem că este valoarea prezisă!
Cum gândește creierul uman
La fel cum creierul nostru își aplică propria logică pentru a prezice ceva, mașinile aplică diverși algoritmi (numiți algoritmi de învățare automată) pentru a ajunge la o valoare prezisă pentru o întrebare. Din nou, aceste valori pot fi aceleași sau diferite de valoarea reală.
Într-o lume competitivă, am dori să știm dacă predicția noastră este corectă sau nu să înțelegem performanța noastră. În același mod, putem determina performanța unui algoritm de învățare automată în funcție de câte predicții a făcut corect.
Deci, ce este un algoritm de învățare automată?
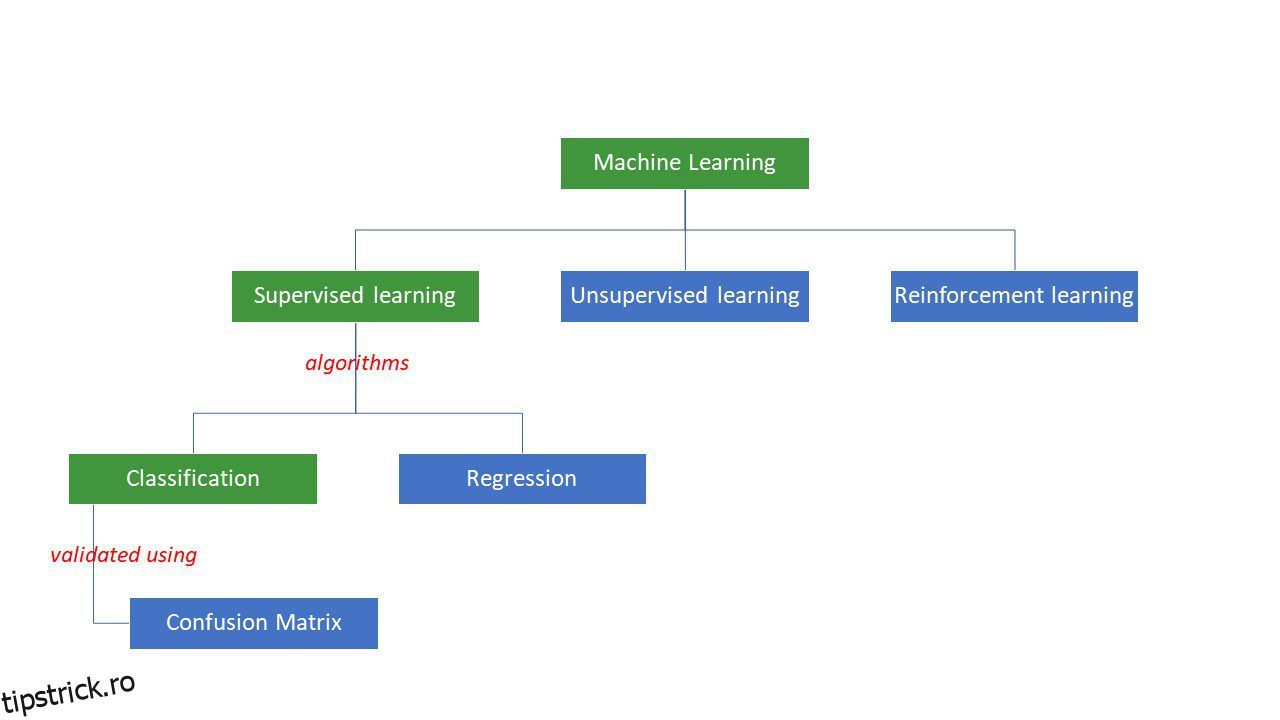
Mașinile încearcă să ajungă la anumite răspunsuri la o problemă aplicând o anumită logică sau un set de instrucțiuni, numite algoritmi de învățare automată. Algoritmii de învățare automată sunt de trei tipuri – supravegheați, nesupravegheați sau întăriți.
 Tipuri de algoritmi de învățare automată
Tipuri de algoritmi de învățare automată
Sunt supravegheate cele mai simple tipuri de algoritmi, în care știm deja răspunsul și antrenăm mașinile să ajungă la acel răspuns antrenând algoritmul cu multe date – la fel ca și cum un copil ar diferenția între oameni de diferite grupe de vârstă prin privindu-le trăsăturile din nou și din nou.
Algoritmii ML supravegheați sunt de două tipuri – clasificare și regresie.
Algoritmii de clasificare clasifică sau sortează datele pe baza unui set de criterii. De exemplu, dacă doriți ca algoritmul dvs. să grupeze clienții în funcție de preferințele lor alimentare – celor cărora le place pizza și celor cărora nu le place pizza, ați folosi un algoritm de clasificare precum arborele de decizie, pădure aleatoare, Bayes naiv sau SVM (Suport Mașină vectorială).
Care dintre acești algoritmi ar face cel mai bine treaba? De ce ar trebui să alegi un algoritm în detrimentul celuilalt?
Introduceți matricea de confuzie…
O matrice de confuzie este o matrice sau un tabel care oferă informații despre cât de precis este un algoritm de clasificare în clasificarea unui set de date. Ei bine, numele nu este pentru a deruta oamenii, dar prea multe predicții incorecte înseamnă probabil că algoritmul a fost confuz😉!
Deci, o matrice de confuzie este o metodă de evaluare a performanței unui algoritm de clasificare.
Cum?
Să presupunem că ați aplicat diferiți algoritmi problemei noastre binare menționate anterior: clasificați (segregați) oamenii în funcție de faptul că le place sau nu pizza. Pentru a evalua algoritmul care are valorile cele mai apropiate de răspunsul corect, ați folosi o matrice de confuzie. Pentru o problemă de clasificare binară (like/dislike, true/false, 1/0), matricea de confuzie oferă patru valori ale grilei, și anume:
- Adevărat pozitiv (TP)
- Adevărat negativ (TN)
- fals pozitiv (FP)
- fals negativ (FN)
Care sunt cele patru grile dintr-o matrice de confuzie?
Cele patru valori determinate folosind matricea de confuzie formează grilele matricei.
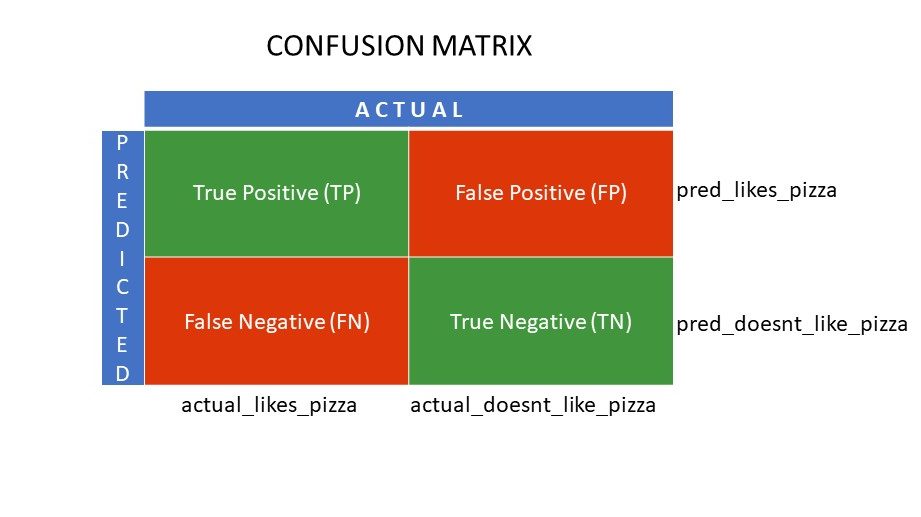 Grile de matrice de confuzie
Grile de matrice de confuzie
True Positive (TP) și True Negative (TN) sunt valorile prezise corect de algoritmul de clasificare,
- TP îi reprezintă pe cei cărora le place pizza, iar modelul i-a clasificat corect,
- TN îi reprezintă pe cei cărora nu le place pizza, iar modelul i-a clasificat corect,
Fals pozitiv (FP) și fals negativ (FN) sunt valorile care sunt prezise greșit de clasificator,
- FP îi reprezintă pe cei cărora nu le place pizza (negativ), dar clasificatorul a prezis că le place pizza (greșit pozitiv). FP se mai numește și eroare de tip I.
- FN îi reprezintă pe cei cărora le place pizza (pozitiv), dar clasificatorul a prezis că nu le place (în mod greșit negativ). FN se mai numește și eroare de tip II.
Pentru a înțelege mai bine conceptul, să luăm un scenariu din viața reală.
Să presupunem că aveți un set de date de 400 de persoane care au fost supuse testului Covid. Acum, ați obținut rezultatele diverșilor algoritmi care au determinat numărul de persoane Covid pozitive și Covid negative.
Iată cele două matrice de confuzie pentru comparație:
Privind la ambele, ați putea fi tentat să spuneți că primul algoritm este mai precis. Dar, pentru a obține un rezultat concret, avem nevoie de niște metrici care pot măsura acuratețea, precizia și multe alte valori care să demonstreze care algoritm este mai bun.
Metrici care utilizează matricea de confuzie și semnificația lor
Principalele valori care ne ajută să decidem dacă clasificatorul a făcut predicțiile corecte sunt:
#1. Rechemare/Sensibilitate
Rechemarea sau Sensibilitatea sau Rata pozitivă adevărată (TPR) sau Probabilitatea de detectare este raportul dintre predicțiile pozitive corecte (TP) și totalul pozitiv (adică, TP și FN).
R = TP/(TP + FN)
Rechemarea este măsura rezultatelor pozitive corecte returnate din numărul de rezultate pozitive corecte care ar fi putut fi produse. O valoare mai mare a Recall înseamnă că există mai puține false negative, ceea ce este bun pentru algoritm. Folosiți Recall atunci când este important să cunoașteți negativul fals. De exemplu, dacă o persoană are mai multe blocaje la inimă și modelul arată că este absolut bine, s-ar putea dovedi a fi fatal.
#2. Precizie
Precizia este măsura rezultatelor pozitive corecte din toate rezultatele pozitive prezise, inclusiv pozitive adevărate și false pozitive.
Pr = TP/(TP + FP)
Precizia este destul de importantă atunci când falsele pozitive sunt prea importante pentru a fi ignorate. De exemplu, dacă o persoană nu are diabet, dar modelul arată acest lucru, iar medicul prescrie anumite medicamente. Acest lucru poate duce la efecte secundare severe.
#3. Specificitate
Specificitatea sau rata negativă adevărată (TNR) reprezintă rezultate negative corecte găsite din toate rezultatele care ar fi putut fi negative.
S = TN/(TN + FP)
Este o măsură a cât de bine identifică clasificatorul dvs. valorile negative.
#4. Precizie
Precizia este numărul de predicții corecte din numărul total de predicții. Deci, dacă ați găsit corect 20 de valori pozitive și 10 negative dintr-un eșantion de 50, acuratețea modelului dvs. va fi de 30/50.
Precizie A = (TP + TN)/(TP + TN + FP + FN)
#5. Prevalența
Prevalența este măsura numărului de rezultate pozitive obținute din toate rezultatele.
P = (TP + FN)/(TP + TN + FP + FN)
#6. Scor F
Uneori, este dificil să compare două clasificatoare (modele) folosind doar Precizie și Recall, care sunt doar mijloace aritmetice ale unei combinații a celor patru grile. În astfel de cazuri, putem folosi Scorul F sau Scorul F1, care este media armonică – care este mai precisă deoarece nu variază prea mult pentru valori extrem de mari. Scorul F mai mare (max 1) indică un model mai bun.
Scor F = 2*Precizie*Recall/ (Recall + Precision)
Când este vital să aveți grijă atât de false pozitive, cât și de false negative, scorul F1 este o măsură bună. De exemplu, cei care nu sunt pozitivi pentru covid (dar algoritmul a arătat acest lucru) nu trebuie să fie izolați în mod inutil. În același mod, cei care sunt pozitivi pentru Covid (dar algoritmul a spus că nu sunt) trebuie izolați.
#7. curbele ROC
Parametri precum acuratețea și precizia sunt valori bune dacă datele sunt echilibrate. Pentru un set de date dezechilibrat, o precizie ridicată poate să nu însemne neapărat că clasificatorul este eficient. De exemplu, 90 din 100 de elevi dintr-un lot cunosc limba spaniolă. Acum, chiar dacă algoritmul tău spune că toți cei 100 știu limba spaniolă, precizia sa va fi de 90%, ceea ce poate oferi o imagine greșită despre model. În cazurile de seturi de date dezechilibrate, valorile precum ROC sunt determinanți mai eficienți.
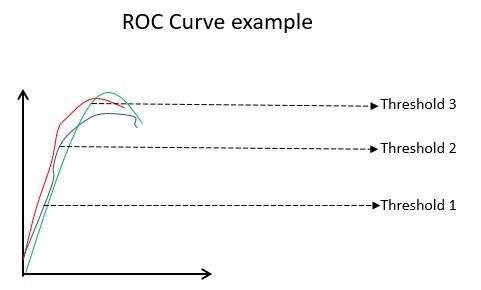 Exemplu de curbă ROC
Exemplu de curbă ROC
Curba ROC (Receiver Operating Characteristic) afișează vizual performanța unui model de clasificare binar la diferite praguri de clasificare. Este o diagramă a TPR (True Positive Rate) față de FPR (False Positive Rate), care este calculată ca (1-Specificie) la diferite valori de prag. Valoarea care se apropie cel mai mult de 45 de grade (stânga sus) în grafic este cea mai precisă valoare de prag. Dacă pragul este prea mare, nu vom avea multe fals pozitive, dar vom obține mai multe fals negative și invers.
În general, atunci când este trasată curba ROC pentru diferite modele, cea care are cea mai mare zonă sub curbă (AUC) este considerat modelul mai bun.
Să calculăm toate valorile metrice pentru matricele noastre de confuzie Clasificatorul I și Clasificatorul II:
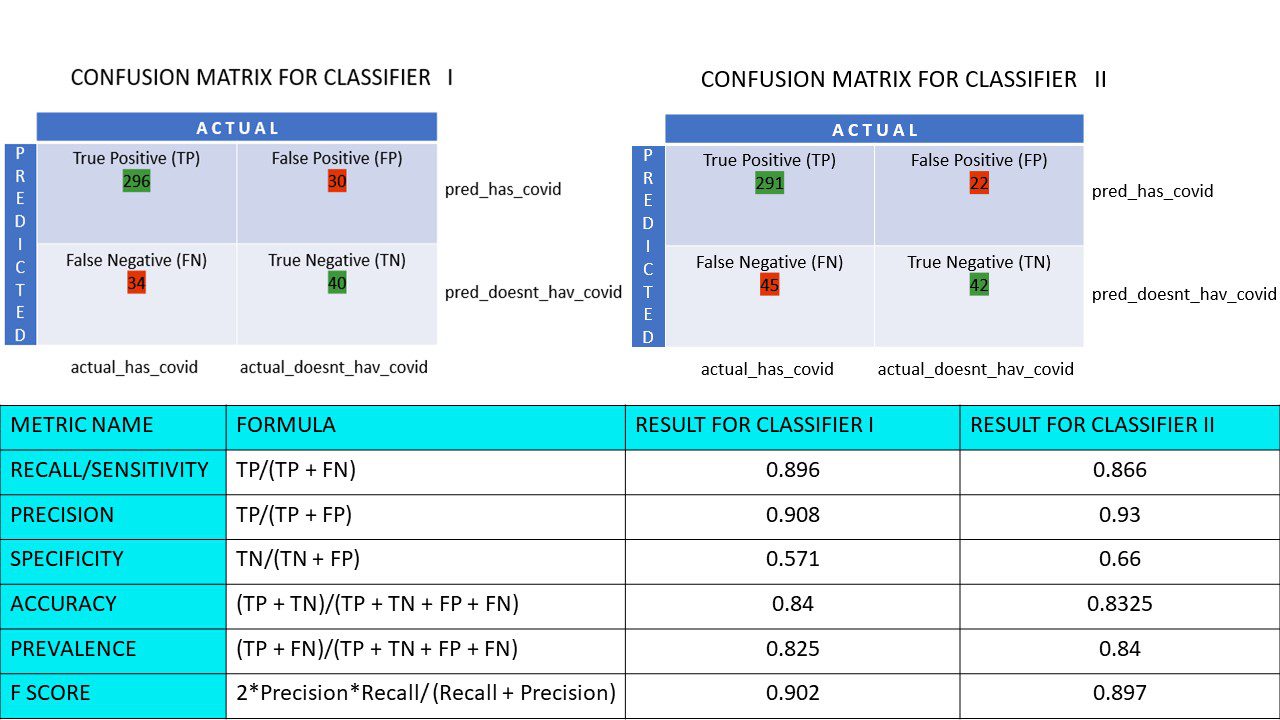 Comparație metrică pentru clasificatorii 1 și 2 din sondajul pizza
Comparație metrică pentru clasificatorii 1 și 2 din sondajul pizza
Vedem că precizia este mai mare în clasificatorul II, în timp ce acuratețea este puțin mai mare în clasificatorul I. Pe baza problemei în cauză, factorii de decizie pot selecta Clasificatorii I sau II.
N x N matrice de confuzie
Până acum, am văzut o matrice de confuzie pentru clasificatorii binari. Dacă ar fi mai multe categorii decât doar da/nu sau like/dislike. De exemplu, dacă algoritmul dvs. a fost de a sorta imaginile de culori roșu, verde și albastru. Acest tip de clasificare se numește clasificare multiclasă. Numărul de variabile de ieșire decide și dimensiunea matricei. Deci, în acest caz, matricea de confuzie va fi 3×3.
 Matrice de confuzie pentru un clasificator cu mai multe clase
Matrice de confuzie pentru un clasificator cu mai multe clase
rezumat
O matrice de confuzie este un sistem de evaluare excelent, deoarece oferă informații detaliate despre performanța unui algoritm de clasificare. Funcționează bine pentru clasificatoare binare, precum și cu mai multe clase, unde există mai mult de 2 parametri de care trebuie îngrijiți. Este ușor să vizualizați o matrice de confuzie și putem genera toate celelalte valori ale performanței, cum ar fi Scorul F, precizia, ROC și acuratețea folosind matricea de confuzie.
De asemenea, puteți vedea cum să alegeți algoritmii ML pentru problemele de regresie.