
Google JAX sau Just After Execution este un cadru dezvoltat de Google pentru a accelera sarcinile de învățare automată.
O puteți considera o bibliotecă pentru Python, care ajută la execuția mai rapidă a sarcinilor, calculul științific, transformările funcțiilor, învățarea profundă, rețelele neuronale și multe altele.
Cuprins
Despre Google JAX
Cel mai fundamental pachet de calcul din Python este pachetul NumPy care are toate funcțiile cum ar fi agregarea, operațiile vectoriale, algebra liniară, manipularea matricelor și matricelor n-dimensionale și multe alte funcții avansate.
Ce se întâmplă dacă am putea accelera și mai mult calculele efectuate folosind NumPy – în special pentru seturi de date uriașe?
Avem ceva care ar putea funcționa la fel de bine pe diferite tipuri de procesoare, cum ar fi un GPU sau TPU, fără modificări de cod?
Ce zici dacă sistemul ar putea efectua transformări ale funcțiilor componabile automat și mai eficient?
Google JAX este o bibliotecă (sau cadru, după cum spune Wikipedia) care face exact asta și poate mult mai mult. A fost creat pentru a optimiza performanța și pentru a efectua eficient învățarea automată (ML) și sarcinile de învățare profundă. Google JAX oferă următoarele funcții de transformare care îl fac unic față de alte biblioteci ML și ajută la calculul științific avansat pentru învățarea profundă și rețelele neuronale:
- Diferențierea automată
- Vectorizare automată
- Paralelizare automată
- Compilare just-in-time (JIT).
Caracteristicile unice ale Google JAX
Toate transformările folosesc XLA (Accelerated Linear Algebra) pentru performanțe mai mari și optimizarea memoriei. XLA este un motor de compilare de optimizare specific domeniului care realizează algebră liniară și accelerează modelele TensorFlow. Utilizarea XLA pe lângă codul dvs. Python nu necesită modificări semnificative ale codului!
Să explorăm în detaliu fiecare dintre aceste caracteristici.
Caracteristicile Google JAX
Google JAX vine cu funcții de transformare componabile importante pentru a îmbunătăți performanța și a îndeplini sarcinile de învățare profundă mai eficient. De exemplu, diferențiere automată pentru a obține gradientul unei funcții și a găsi derivate de orice ordin. În mod similar, paralelizarea automată și JIT pentru a efectua mai multe sarcini în paralel. Aceste transformări sunt cheie pentru aplicații precum robotica, jocurile și chiar cercetarea.
O funcție de transformare componabilă este o funcție pură care transformă un set de date într-o altă formă. Ele sunt numite componabile deoarece sunt autonome (adică, aceste funcții nu au dependențe de restul programului) și sunt apatride (adică aceeași intrare va avea întotdeauna aceeași ieșire).
Y(x) = T: (f(x))
În ecuația de mai sus, f(x) este funcția inițială pe care se aplică o transformare. Y(x) este funcția rezultantă după aplicarea transformării.
De exemplu, dacă aveți o funcție numită „total_bill_amt” și doriți ca rezultatul ca o transformare a funcției, puteți utiliza pur și simplu transformarea pe care o doriți, să spunem gradient (grad):
grad_total_bill = grad(total_bill_amt)
Prin transformarea funcțiilor numerice folosind funcții precum grad(), putem obține cu ușurință derivatele lor de ordin superior, pe care le putem folosi pe scară largă în algoritmi de optimizare a învățării profunde, cum ar fi coborârea gradientului, făcând astfel algoritmii mai rapidi și mai eficienți. În mod similar, folosind jit(), putem compila programe Python just-in-time (lene).
#1. Diferențierea automată
Python folosește funcția autograd pentru a diferenția automat codul NumPy și codul nativ Python. JAX folosește o versiune modificată a autogradului (adică grad) și combină XLA (Algebra liniară accelerată) pentru a efectua diferențierea automată și pentru a găsi derivate de orice ordine pentru GPU (Unități de procesare grafică) și TPU (Unități de procesare a tensorului).]
Notă rapidă despre TPU, GPU și CPU: CPU sau unitatea centrală de procesare gestionează toate operațiunile de pe computer. GPU este un procesor suplimentar care îmbunătățește puterea de calcul și rulează operațiuni high-end. TPU este o unitate puternică dezvoltată special pentru sarcini complexe și grele, cum ar fi AI și algoritmi de învățare profundă.
Pe aceleași linii ca și funcția autograd, care poate diferenția prin bucle, recursiuni, ramuri și așa mai departe, JAX folosește funcția grad() pentru gradienți în mod invers (backpropagation). De asemenea, putem diferenția o funcție de orice ordin folosind grad:
grad(grad(grad(sin θ))) (1.0)
Diferențierea automată de ordin superior
După cum am menționat anterior, gradul este destul de util în găsirea derivatelor parțiale ale unei funcții. Putem folosi o derivată parțială pentru a calcula coborârea gradientului unei funcții de cost în raport cu parametrii rețelei neuronale în învățarea profundă pentru a minimiza pierderile.
Calcularea derivatei parțiale
Să presupunem că o funcție are mai multe variabile, x, y și z. Găsirea derivatei unei variabile menținând constante celelalte variabile se numește derivată parțială. Să presupunem că avem o funcție,
f(x,y,z) = x + 2y + z2
Exemplu pentru a arăta derivata parțială
Derivata parțială a lui x va fi ∂f/∂x, ceea ce ne spune cum se modifică o funcție pentru o variabilă atunci când altele sunt constante. Dacă efectuăm acest lucru manual, trebuie să scriem un program de diferențiere, să îl aplicăm pentru fiecare variabilă și apoi să calculăm coborârea gradientului. Aceasta ar deveni o afacere complexă și consumatoare de timp pentru mai multe variabile.
Diferențierea automată descompune funcția într-un set de operații elementare, cum ar fi +, -, *, / sau sin, cos, tan, exp, etc. și apoi aplică regula lanțului pentru a calcula derivata. Putem face acest lucru atât în modul înainte, cât și în mod invers.
Acesta nu este! Toate aceste calcule se întâmplă atât de repede (ei bine, gândiți-vă la un milion de calcule similare cu cele de mai sus și timpul necesar!). XLA are grijă de viteză și performanță.
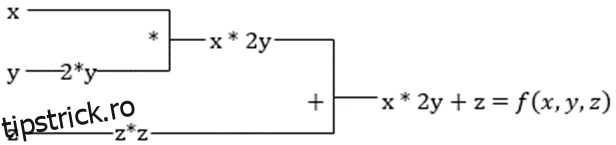
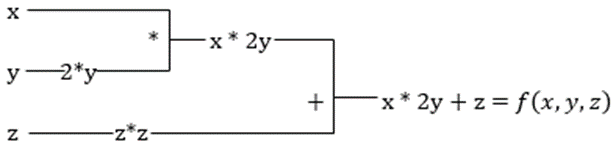
#2. Algebră liniară accelerată
Să luăm ecuația anterioară. Fără XLA, calculul va dura trei (sau mai multe) nuclee, unde fiecare nucleu va îndeplini o sarcină mai mică. De exemplu,
Kernel k1 –> x * 2y (înmulțire)
k2 –> x * 2y + z (adunare)
k3 –> Reducere
Dacă aceeași sarcină este efectuată de XLA, un singur nucleu se ocupă de toate operațiunile intermediare prin fuzionarea lor. Rezultatele intermediare ale operațiilor elementare sunt transmise în flux în loc să le stocheze în memorie, economisind astfel memoria și sporind viteza.
#3. Compilare just-in-time
JAX utilizează intern compilatorul XLA pentru a crește viteza de execuție. XLA poate crește viteza CPU, GPU și TPU. Toate acestea sunt posibile folosind executarea codului JIT. Pentru a folosi acest lucru, putem folosi jit prin import:
from jax import jit def my_function(x): …………some lines of code my_function_jit = jit(my_function)
O altă modalitate este de a decora jit peste definiția funcției:
@jit def my_function(x): …………some lines of code
Acest cod este mult mai rapid, deoarece transformarea va returna versiunea compilată a codului către apelant, mai degrabă decât să folosească interpretul Python. Acest lucru este util în special pentru intrări vectoriale, cum ar fi matrice și matrice.
Același lucru este valabil și pentru toate funcțiile Python existente. De exemplu, funcții din pachetul NumPy. În acest caz, ar trebui să importam jax.numpy ca jnp, mai degrabă decât NumPy:
import jax import jax.numpy as jnp x = jnp.array([[1,2,3,4], [5,6,7,8]])
Odată ce faci acest lucru, obiectul matrice JAX de bază numit DeviceArray înlocuiește matricea standard NumPy. DeviceArray este leneș – valorile sunt păstrate în accelerator până când este nevoie. Aceasta înseamnă, de asemenea, că programul JAX nu așteaptă ca rezultatele să revină la programul apelant (Python), urmând astfel o expediere asincronă.
#4. Vectorizare automată (vmap)
Într-o lume tipică a învățării automate, avem seturi de date cu un milion sau mai multe puncte de date. Cel mai probabil, am efectua niște calcule sau manipulări pe fiecare sau pe majoritatea acestor puncte de date – ceea ce este o sarcină care necesită foarte mult timp și memorie! De exemplu, dacă doriți să găsiți pătratul fiecărui punct de date din setul de date, primul lucru la care v-ați gândi este să creați o buclă și să luați pătratul unul câte unul – argh!
Dacă creăm aceste puncte ca vectori, am putea face toate pătratele dintr-o singură mișcare, efectuând manipulări vectoriale sau matrice asupra punctelor de date cu NumPy-ul nostru preferat. Și dacă programul dvs. ar putea face acest lucru automat – puteți cere ceva mai mult? Exact asta face JAX! Vă poate vectoriza automat toate punctele dvs. de date, astfel încât să puteți efectua cu ușurință orice operațiuni asupra lor – făcând algoritmii mult mai rapidi și mai eficienți.
JAX folosește funcția vmap pentru auto-vectorizare. Luați în considerare următoarea matrice:
x = jnp.array([1,2,3,4,5,6,7,8,9,10]) y = jnp.square(x)
Făcând doar cele de mai sus, metoda pătratului se va executa pentru fiecare punct din matrice. Dar dacă faci următoarele:
vmap(jnp.square(x))
Pătratul metodei se va executa o singură dată, deoarece punctele de date sunt acum vectorizate automat utilizând metoda vmap înainte de a executa funcția, iar bucla este împinsă în jos la nivelul elementar de operare – rezultând mai degrabă o multiplicare matriceală decât o multiplicare scalară, oferind astfel performanțe mai bune. .
#5. Programare SPMD (pmap)
SPMD – sau programarea cu un singur program pentru date multiple este esențială în contextele de învățare profundă – ați aplica adesea aceleași funcții pe diferite seturi de date care se află pe mai multe GPU-uri sau TPU-uri. JAX are o funcție numită pompă, care permite programarea în paralel pe mai multe GPU-uri sau orice accelerator. La fel ca JIT, programele care folosesc pmap vor fi compilate de XLA și executate simultan în toate sistemele. Această paralelizare automată funcționează atât pentru calcule înainte cât și invers.
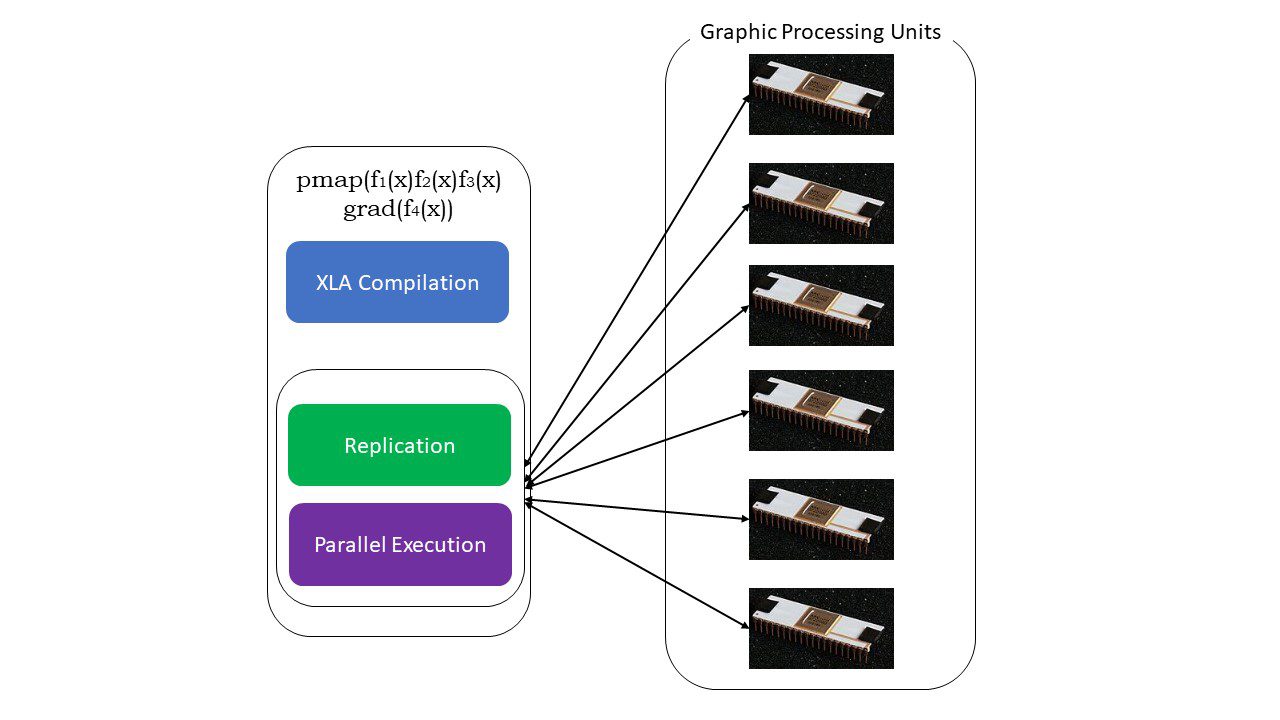 Cum funcționează pmap
Cum funcționează pmap
Putem aplica, de asemenea, transformări multiple dintr-o singură mișcare, în orice ordine pe orice funcție ca:
pmap(vmap(jit(grad (f(x)))))
Transformări componabile multiple
Limitări ale Google JAX
Dezvoltatorii Google JAX s-au gândit bine la accelerarea algoritmilor de învățare profundă, introducând toate aceste transformări extraordinare. Funcțiile și pachetele de calcul științific sunt pe linia NumPy, așa că nu trebuie să vă faceți griji cu privire la curba de învățare. Cu toate acestea, JAX are următoarele limitări:
- Google JAX este încă în fazele incipiente de dezvoltare și, deși scopul său principal este optimizarea performanței, nu oferă prea multe beneficii pentru calculul CPU. NumPy pare să funcționeze mai bine, iar utilizarea JAX poate doar să adauge la suprasarcina.
- JAX se află încă în stadii de cercetare sau incipiente și are nevoie de mai multe reglaje pentru a atinge standardele de infrastructură ale cadrelor precum TensorFlow, care sunt mai stabilite și au mai multe modele predefinite, proiecte open-source și materiale de învățare.
- Începând de acum, JAX nu acceptă sistemul de operare Windows – veți avea nevoie de o mașină virtuală pentru a o face să funcționeze.
- JAX funcționează numai pe funcții pure – cele care nu au niciun efect secundar. Pentru funcțiile cu efecte secundare, JAX poate să nu fie o opțiune bună.
Cum să instalați JAX în mediul dvs. Python
Dacă aveți o configurare python pe sistemul dvs. și doriți să rulați JAX pe mașina dvs. locală (CPU), utilizați următoarele comenzi:
pip install --upgrade pip pip install --upgrade "jax[cpu]"
Dacă doriți să rulați Google JAX pe un GPU sau TPU, urmați instrucțiunile date pe GitHub JAX pagină. Pentru a configura Python, vizitați Descărcări oficiale python pagină.
Concluzie
Google JAX este excelent pentru a scrie algoritmi eficienți de învățare profundă, robotică și cercetare. În ciuda limitărilor, este utilizat pe scară largă cu alte cadre precum Haiku, Flax și multe altele. Veți putea aprecia ce face JAX atunci când rulați programe și veți vedea diferențele de timp în executarea codului cu și fără JAX. Puteți începe prin a citi documentația oficială Google JAXcare este destul de cuprinzător.