
Dacă sunteți începător în analiza datelor mari, s-ar putea să vă aflați pe radar multitudinea de instrumente apache; cu toate acestea, totalitatea diferitelor instrumente poate deveni confuză și, uneori, copleșitoare.
Această postare va rezolva această confuzie și va explica ce sunt Apache Hive și Impala și ce le face diferite unul de celălalt!
Cuprins
Apache Hive
Apache Hive este o interfață de acces la date SQL pentru platforma Apache Hadoop. Hive vă permite să interogați, să agregați și să analizați date folosind sintaxa SQL.
O schemă de acces la citire este utilizată pentru datele din sistemul de fișiere HDFS, permițându-vă să tratați datele ca la un tabel obișnuit sau un SGBD relațional. Interogările HiveQL sunt traduse în cod Java pentru joburile MapReduce.
Interogările Hive sunt scrise în limbajul de interogare HiveQL, care se bazează pe limbajul SQL, dar nu are suport complet pentru standardul SQL-92.
Cu toate acestea, acest limbaj permite programatorilor să-și folosească interogările atunci când este incomod sau ineficient să folosească caracteristicile HiveQL. HiveQL poate fi extins cu funcții scalare definite de utilizator (UDF), agregari (coduri UDAF) și funcții de tabel (UDTF).
Cum funcționează Apache Hive
Apache Hive traduce programele scrise în limbajul HiveQL (aproape de SQL) în una sau mai multe sarcini MapReduce, Apache Tez sau Apache Spark. Acestea sunt trei motoare de execuție care pot fi lansate pe Hadoop. Apoi, Apache Hive organizează datele într-o matrice pentru fișierul Hadoop Distributed File System (HDFS) pentru a rula joburile pe un cluster pentru a produce un răspuns.
Tabelele Apache Hive sunt similare cu bazele de date relaționale, iar unitățile de date sunt organizate de la cea mai semnificativă unitate la cea mai granulară. Bazele de date sunt matrice compuse din partiții, care pot fi din nou împărțite în „găleți”.
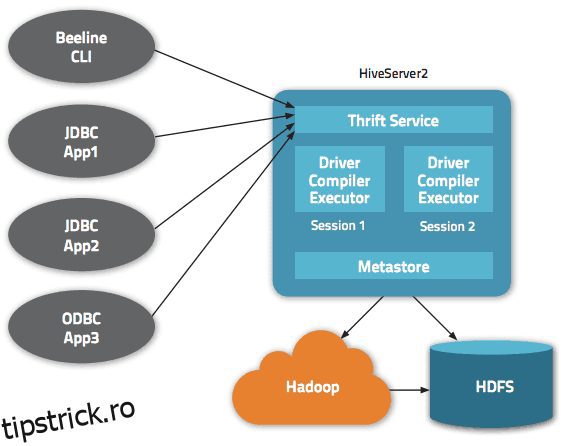
Datele sunt accesibile prin HiveQL. În cadrul fiecărei baze de date, datele sunt numerotate, iar fiecare tabel corespunde unui director HDFS.
Sunt disponibile mai multe interfețe în arhitectura Apache Hive, cum ar fi interfața web, CLI sau clienții externi.
Într-adevăr, serverul „Apache Hive Thrift” permite clienților la distanță să trimită comenzi și solicitări către Apache Hive folosind diferite limbaje de programare. Directorul central al Apache Hive este un „metamagazin” care conține toate informațiile.
Motorul care face ca Hive să funcționeze se numește „șofer”. Include un compilator și un optimizator pentru a determina planul optim de execuție.
În cele din urmă, securitatea este asigurată de Hadoop. Prin urmare, se bazează pe Kerberos pentru autentificarea reciprocă între client și server. Permisiunea pentru fișierele nou create în Apache Hive este dictată de HDFS, permițând autorizarea utilizatorului, grupului sau în alt mod.
Caracteristicile lui Hive
- Acceptă motorul de calcul Hadoop și Spark
- Utilizează HDFS și funcționează ca un depozit de date.
- Utilizează MapReduce și acceptă ETL
- Datorită HDFS, are toleranță la erori similară cu Hadoop
Apache Hive: Beneficii
Apache Hive este o soluție ideală pentru interogări și analiza datelor. Face posibilă obținerea de perspective calitative, oferind un avantaj competitiv și facilitând receptivitatea la cererea pieței.
Printre principalele avantaje ale Apache Hive, putem aminti ușurința de utilizare legată de limbajul său „SQL-friendly”. În plus, accelerează inserarea inițială a datelor, deoarece datele nu trebuie să fie citite sau numerotate de pe un disc în formatul intern al bazei de date.
Știind că datele sunt stocate în HDFS, este posibilă stocarea unor seturi mari de date de până la sute de petabytes de date pe Apache Hive. Această soluție este mult mai scalabilă decât o bază de date tradițională. Știind că este un serviciu cloud, Apache Hive permite utilizatorilor să lanseze rapid servere virtuale în funcție de fluctuațiile sarcinilor de lucru (adică sarcini).
Securitatea este, de asemenea, un aspect în care Hive are performanțe mai bune, cu capacitatea sa de a replica sarcinile de lucru critice pentru recuperare în cazul unei probleme. În cele din urmă, capacitatea de lucru este de neegalat, deoarece poate efectua până la 100.000 de solicitări pe oră.
Apache Impala
Apache Impala este un motor de interogări SQL masiv paralel pentru execuția interactivă a interogărilor SQL pe datele stocate în Apache Hadoop, scrise în C++ și distribuite sub licența Apache 2.0.
Impala se mai numește motor MPP (Massively Parallel Processing), un DBMS distribuit și chiar o bază de date SQL-on-Hadoop.

Impala funcționează în modul distribuit, în care instanțe de proces rulează pe diferite noduri de cluster, primind, programând și coordonând cererile clienților. În acest caz, este posibilă executarea paralelă a fragmentelor de interogare SQL.
Clienții sunt utilizatori și aplicații care trimit interogări SQL împotriva datelor stocate în Apache Hadoop (HBase și HDFS) sau Amazon S3. Interacțiunea cu Impala are loc prin interfața web HUE (Hadoop User Experience), ODBC, JDBC și shell-ul de linie de comandă Impala Shell.
Impala depinde din punct de vedere infrastructural de un alt instrument popular SQL-on-Hadoop, Apache Hive, care utilizează depozitul său de metadate. În special, Hive Metastore îi informează pe Impala despre disponibilitatea și structura bazelor de date.
La crearea, modificarea și ștergerea obiectelor de schemă sau încărcarea datelor în tabele prin instrucțiuni SQL, modificările corespunzătoare ale metadatelor sunt propagate automat la toate nodurile Impala folosind un serviciu de director specializat.
Componentele cheie ale Impala sunt următoarele executabile:
- Impalad sau Impala daemon este un serviciu de sistem care programează și execută interogări pe date HDFS, HBase și Amazon S3. Un proces impalad rulează pe fiecare nod de cluster.
- Statestore este un serviciu de denumire care urmărește locația și starea tuturor instanțelor impalad din cluster. O instanță a acestui serviciu de sistem rulează pe fiecare nod și pe serverul principal (Name Node).
- Catalog este un serviciu de coordonare a metadatelor care propagă modificările de la instrucțiunile Impala DDL și DML către toate nodurile Impala afectate, astfel încât tabele noi sau datele nou încărcate să fie imediat vizibile pentru orice nod din cluster. Se recomandă ca o instanță a Catalog să ruleze pe aceeași gazdă de cluster ca demonul Statestored.
Cum funcționează Apache Impala
Impala, ca și Apache Hive, utilizează un limbaj de interogare declarativ similar, Hive Query Language (HiveQL), care este un subset al SQL92, în loc de SQL.
Executarea efectivă a cererii în Impala este următoarea:
Aplicația client trimite o interogare SQL prin conectarea la orice impalad prin interfețe standardizate de driver ODBC sau JDBC. Impaladul conectat devine coordonatorul cererii curente.
Interogarea SQL este analizată pentru a determina sarcinile pentru instanțe impalad din cluster; apoi, se construiește planul optim de execuție a interogării.
Impalad accesează direct HDFS și HBase folosind instanțe locale ale serviciilor de sistem pentru a furniza date. Spre deosebire de Apache Hive, o astfel de interacțiune directă economisește semnificativ timpul de execuție a interogărilor, deoarece rezultatele intermediare nu sunt salvate.
Ca răspuns, fiecare demon returnează date către impaladul coordonator, trimițând rezultatele înapoi către client.
Caracteristicile lui Impala
- Suport pentru procesarea în timp real în memorie
- SQL prietenos
- Suportă sisteme de stocare precum HDFS, Apache HBase și Amazon S3
- Acceptă integrarea cu instrumente BI precum Pentaho și Tableau
- Utilizează sintaxa HiveQL
Apache Impala: Beneficii
Impala evită posibila suprasarcină de pornire deoarece toate procesele demonului de sistem sunt pornite direct la pornire. Economisește semnificativ timpul de execuție a interogărilor. O creștere suplimentară a vitezei Impala este că acest instrument SQL pentru Hadoop, spre deosebire de Hive, nu stochează rezultate intermediare și accesează HDFS sau HBase direct.
În plus, Impala generează cod de program în timpul execuției și nu la compilare, așa cum face Hive. Cu toate acestea, un efect secundar al performanței de mare viteză a lui Impala este fiabilitatea redusă.
În special, dacă nodul de date scade în timpul execuției unei interogări SQL, instanța Impala va reporni, iar Hive va continua să păstreze o conexiune la sursa de date, oferind toleranță la erori.
Alte beneficii ale Impala includ suport încorporat pentru un protocol Kerberos de autentificare a rețelei securizate, prioritizarea și capacitatea de a gestiona coada de solicitări și suport pentru formate populare de Big Data, cum ar fi LZO, Avro, RCFile, Parquet și Sequence.
Hive Vs Impala: Asemănări
Hive și Impala sunt distribuite gratuit sub licența Apache Software Foundation și se referă la instrumentele SQL pentru lucrul cu datele stocate într-un cluster Hadoop. În plus, folosesc și sistemul de fișiere distribuit HDFS.
Impala și Hive implementează diferite sarcini cu un accent comun pe procesarea SQL a datelor mari stocate într-un cluster Apache Hadoop. Impala oferă o interfață asemănătoare SQL, permițându-vă să citiți și să scrieți tabele Hive, permițând astfel un schimb ușor de date.
În același timp, Impala face operațiunile SQL pe Hadoop destul de rapide și eficiente, permițând utilizarea acestui DBMS în proiecte de cercetare de analiză a datelor Big Data. Ori de câte ori este posibil, Impala funcționează cu o infrastructură existentă Apache Hive deja utilizată pentru a executa interogări SQL în loturi de lungă durată.
De asemenea, Impala își stochează definițiile tabelelor într-un metastore, o bază de date tradițională MySQL sau PostgreSQL, adică în același loc în care Hive stochează date similare. Permite lui Impala să acceseze tabelele Hive atâta timp cât toate coloanele utilizează tipurile de date, formatele de fișiere și codecurile de compresie acceptate de Impala.
Hive Vs Impala: Diferențe

Limbaj de programare
Hive este scris în Java, în timp ce Impala este scris în C++. Cu toate acestea, Impala folosește și unele UDF-uri Hive bazate pe Java.
Cazuri de utilizare
Inginerii de date folosesc Hive în procesele ETL (Extract, Transform, Load), de exemplu, pentru joburi în loturi de lungă durată pe seturi mari de date, de exemplu, în agregatoare de călătorie și sisteme de informații aeroportuare. La rândul său, Impala este destinat în principal analiștilor și cercetătorilor de date și este utilizat în principal în sarcini precum business intelligence.
Performanţă
Impala execută interogări SQL în timp real, în timp ce Hive se caracterizează printr-o viteză scăzută de procesare a datelor. Cu interogări SQL simple, Impala poate rula de 6-69 de ori mai rapid decât Hive. Cu toate acestea, Hive gestionează mai bine interogările complexe.
Latență/debit
Debitul Hive este semnificativ mai mare decât cel al Impala. Caracteristica LLAP (Live Long and Process), care permite stocarea în cache a interogărilor în memorie, oferă Hive performanțe bune la nivel scăzut.
LLAP include servicii de sistem pe termen lung (daemoni), care vă permit să interacționați direct cu nodurile de date HDFS și să înlocuiți structura de interogare DAG strâns integrată (Graf aciclic direcționat) – un model de grafic utilizat activ în calculul Big Data.
Toleranță la erori
Hive este un sistem tolerant la erori care păstrează toate rezultatele intermediare. De asemenea, afectează în mod pozitiv scalabilitatea, dar duce la o scădere a vitezei de procesare a datelor. La rândul său, Impala nu poate fi numită o platformă tolerantă la erori, deoarece este mai mult legată de memorie.
Conversia codului
Hive generează expresii de interogare în timpul compilării, în timp ce Impala le generează în timpul execuției. Hive se caracterizează printr-o problemă de „pornire la rece” la prima lansare a aplicației; interogările sunt convertite lent datorită necesității de a stabili o conexiune la sursa de date.
Impala nu are acest tip de pornire. Serviciile de sistem necesare (demonii) pentru procesarea interogărilor SQL sunt pornite în momentul pornirii, ceea ce accelerează munca.
Suport de stocare
Impala acceptă formatele LZO, Avro și Parquet, în timp ce Hive funcționează cu Text simplu și ORC. Cu toate acestea, ambele acceptă formatele RCFIle și Sequence.
Apache HiveApache ImpalaLanguage JavaC++ Cazuri de utilizareIngineria datelorAnaliză și analizăPerformanță Ridicată pentru interogări simple Latență relativ scăzută Mai multă latență datorită stocării în cacheToleranță mai puțin latentă la eroriMai tolerant datorită MapReduceMai puțin tolerant datorită suportului MPPConversionLentă datorită pornirii la rece SAU conversie mai rapidă, Parquet și Avage
Cuvinte finale
Hive și Impala nu concurează, ci se completează eficient unul pe celălalt. Chiar dacă există diferențe semnificative între cele două, există și destul de multe în comun și alegerea unuia față de celălalt depinde de datele și cerințele particulare ale proiectului.
De asemenea, puteți explora comparații directe între Hadoop și Spark.
.