

Știința datelor este pentru oricine îi place să dezlege lucruri încurcate și să descopere minuni ascunse într-o aparentă mizerie.
E ca și cum ai căuta ace în căți de fân; doar că oamenii de știință de date nu trebuie să-și murdărească deloc mâinile. Folosind instrumente fanteziste cu diagrame colorate și uitându-se la grămezi de numere, ei doar se scufundă în carpi de fân de date și găsesc ace valoroase sub formă de perspective de mare valoare comercială.
Un tipic cercetător de date caseta de instrumente ar trebui să includă cel puțin un articol din fiecare dintre aceste categorii: baze de date relaționale, baze de date NoSQL, cadre de date mari, instrumente de vizualizare, instrumente de scraping, limbaje de programare, IDE-uri și instrumente de învățare profundă.
Cuprins
Baze de date relaționale
O bază de date relațională este o colecție de date structurate în tabele cu atribute. Tabelele pot fi legate între ele, definind relații și restricții și creând ceea ce se numește un model de date. Pentru a lucra cu baze de date relaționale, utilizați de obicei un limbaj numit SQL (Structured Query Language).
Aplicațiile care gestionează structura și datele din bazele de date relaționale se numesc RDBMS (Relational DataBase Management Systems). Există o mulțime de astfel de aplicații, iar cele mai relevante au început recent să se concentreze pe domeniul științei datelor, adăugând funcționalități pentru a lucra cu depozite de date mari și pentru a aplica tehnici precum analiza datelor și învățarea automată.
SQL Server
RDBMS de la Microsoft, a evoluat de mai bine de 20 de ani prin extinderea constantă a funcționalității întreprinderii. Încă din versiunea sa din 2016, SQL Server oferă un portofoliu de servicii care includ suport pentru codul R încorporat. SQL Server 2017 ridică pariul prin redenumirea Serviciilor R în Servicii de limbaj mașină și adăugând suport pentru limbajul Python (mai multe despre aceste două limbi mai jos).
Cu aceste completări importante, SQL Server vizează oamenii de știință de date care ar putea să nu aibă experiență cu Transact SQL, limbajul de interogare nativ al Microsoft SQL Server.

SQL Server este departe de a fi un produs gratuit. Puteți cumpăra licențe pentru a-l instala pe un Windows Server (prețul va varia în funcție de numărul de utilizatori concurenți) sau îl puteți utiliza ca serviciu contra cost, prin cloud-ul Microsoft Azure. Învățarea Microsoft SQL Server este ușoară.
MySQL
Pe partea de software open-source, MySQL are coroana de popularitate a RDBMS-urilor. Deși Oracle îl deține în prezent, este încă gratuit și cu sursă deschisă în conformitate cu termenii unei licențe publice generale GNU. Majoritatea aplicațiilor bazate pe web folosesc MySQL ca depozit de date de bază, datorită respectării standardului SQL.
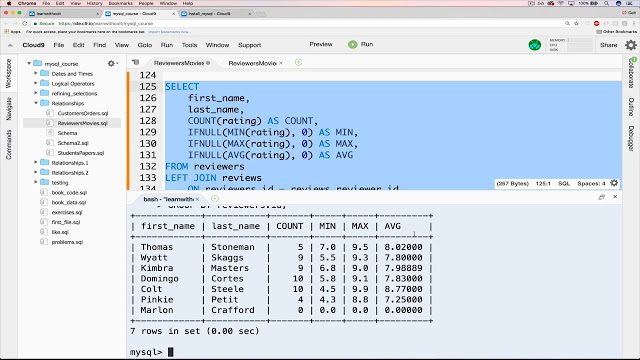
De asemenea, ajută la popularitatea sa procedurile sale ușoare de instalare, comunitatea sa mare de dezvoltatori, tone de documentație cuprinzătoare și instrumente terțe, cum ar fi phpMyAdmin, care simplifică activitățile de gestionare de zi cu zi. Deși MySQL nu are funcții native pentru analiza datelor, deschiderea sa permite integrarea sa cu aproape orice instrument de vizualizare, raportare și business intelligence pe care îl alegeți.
PostgreSQL
O altă opțiune RDBMS open-source este PoztgreSQL. Deși nu este la fel de popular ca MySQL, PostgreSQL se remarcă prin flexibilitate și extensibilitate și prin suportul pentru interogări complexe, cele care depășesc instrucțiunile de bază precum SELECT, WHERE și GROUP BY.
Aceste caracteristici îi permit să câștige popularitate în rândul cercetătorilor de date. O altă caracteristică interesantă este suportul pentru medii multiple, care îi permite să fie utilizat în medii cloud și on-premise, sau într-o combinație a ambelor, cunoscute în mod obișnuit ca medii cloud hibride.
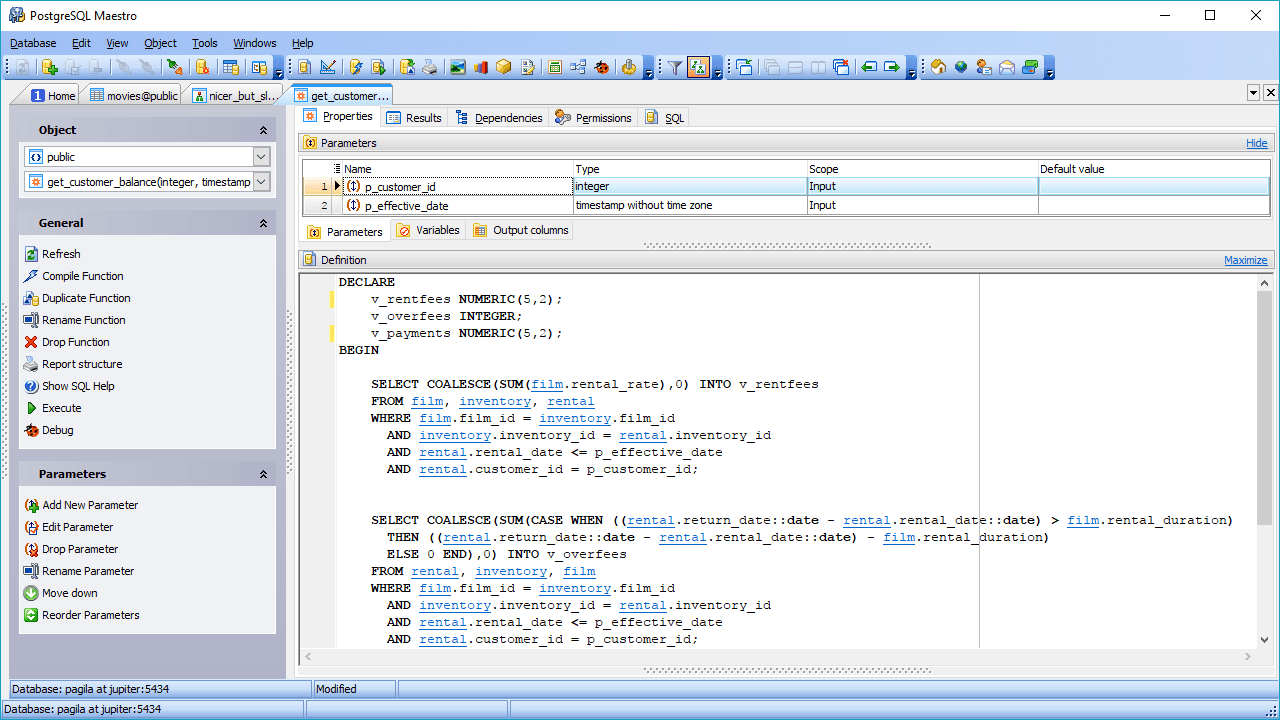
PostgreSQL este capabil să combine procesarea analitică online (OLAP) cu procesarea tranzacțiilor online (OLTP), lucrând într-un mod numit procesare tranzacțională/analitică hibridă (HTAP). De asemenea, este potrivit pentru a lucra cu date mari, datorită adăugării PostGIS pentru date geografice și JSON-B pentru documente. PostgreSQL acceptă și date nestructurate, ceea ce le permite să fie în ambele categorii: baze de date SQL și NoSQL.
baze de date NoSQL
Cunoscut și ca baze de date non-relaționale, acest tip de depozit de date oferă acces mai rapid la structurile de date non-tabulare. Câteva exemple ale acestor structuri sunt grafice, documente, coloane largi, valori cheie, printre multe altele. Depozitele de date NoSQL pot lăsa deoparte coerența datelor în favoarea altor beneficii, cum ar fi disponibilitatea, partiționarea și viteza de acces.
Deoarece nu există SQL în depozitele de date NoSQL, singura modalitate de a interoga acest tip de bază de date este utilizarea limbajelor de nivel scăzut și nu există un astfel de limbaj care să fie la fel de larg acceptat ca SQL. În plus, nu există specificații standard pentru NoSQL. De aceea, în mod ironic, unele baze de date NoSQL încep să adauge suport pentru scripturile SQL.
MongoDB
MongoDB este un sistem popular de baze de date NoSQL, care stochează date sub formă de documente JSON. Accentul său se pune pe scalabilitate și flexibilitate de a stoca datele într-un mod nestructurat. Aceasta înseamnă că nu există o listă de câmpuri fixe care să fie respectată în toate elementele stocate. Mai mult, structura datelor poate fi modificată în timp, ceea ce într-o bază de date relațională implică un risc mare de a afecta aplicațiile care rulează.

Tehnologia din MongoDB permite indexare, interogări ad-hoc și agregare care oferă o bază solidă pentru analiza datelor. Natura distribuită a bazei de date oferă disponibilitate ridicată, scalare și distribuție geografică fără a fi nevoie de instrumente sofisticate.
Redis
Acest una este o altă opțiune în fața open-source, NoSQL. Practic este un depozit de structuri de date care funcționează în memorie și, pe lângă furnizarea de servicii de baze de date, funcționează și ca memorie cache și broker de mesaje.

Acesta acceptă o multitudine de structuri de date neconvenționale, inclusiv hashuri, indici geospațiali, liste și seturi sortate. Este foarte potrivit pentru știința datelor datorită performanței sale înalte în sarcinile mari de date, cum ar fi calcularea intersecțiilor setului, sortarea listelor lungi sau generarea de clasamente complexe. Motivul performanței remarcabile a lui Redis este funcționarea sa în memorie. Poate fi configurat pentru a păstra datele în mod selectiv.
Cadre de date mari
Să presupunem că trebuie să analizați datele generate de utilizatorii de Facebook pe parcursul unei luni. Vorbim despre fotografii, videoclipuri, mesaje, toate acestea. Ținând cont că mai mult de 500 de terabytes de date sunt adăugați în fiecare zi rețelei de socializare de către utilizatorii acesteia, este greu de măsurat volumul reprezentat de o lună întreagă de date ale acesteia.
Pentru a manipula acea cantitate imensă de date într-un mod eficient, aveți nevoie de un cadru adecvat capabil să calculeze statistici printr-o arhitectură distribuită. Există două dintre cadrele care conduc piața: Hadoop și Spark.
Hadoop
Ca cadru de date mari, Hadoop se ocupă de complexitățile asociate cu regăsirea, procesarea și stocarea unor grămezi uriașe de date. Hadoop operează într-un mediu distribuit, compus din clustere de computere care procesează algoritmi simpli. Există un algoritm de orchestrare, numit MapReduce, care împarte sarcinile mari în părți mici și apoi distribuie acele sarcini mici între grupurile disponibile.

Hadoop este recomandat pentru depozitele de date de clasă enterprise care necesită acces rapid și disponibilitate ridicată, toate acestea într-o schemă cu costuri reduse. Dar aveți nevoie de un administrator Linux cu deep Cunoștințe Hadoop pentru a menține cadrul și a rula.
Scânteie
Hadoop nu este singurul cadru disponibil pentru manipularea datelor mari. Un alt nume mare în acest domeniu este Scânteie. Motorul Spark a fost conceput pentru a depăși Hadoop în ceea ce privește viteza de analiză și ușurința în utilizare. Aparent, a atins acest obiectiv: unele comparații spun că Spark rulează de până la 10 ori mai rapid decât Hadoop atunci când lucrează pe un disc și de 100 de ori mai rapid funcționează în memorie. De asemenea, necesită un număr mai mic de mașini pentru a procesa aceeași cantitate de date.

Pe lângă viteză, un alt beneficiu al Spark este suportul pentru procesarea fluxului. Acest tip de prelucrare a datelor, numită și procesare în timp real, implică intrarea și ieșirea continuă a datelor.
Instrumente de vizualizare
O glumă comună între oamenii de știință a datelor spune că, dacă torturiți datele suficient de mult, acestea vă vor mărturisi ceea ce trebuie să știți. În acest caz, „tortura” înseamnă a manipula datele prin transformarea și filtrarea lor, pentru a le vizualiza mai bine. Și aici vin în scenă instrumentele de vizualizare a datelor. Aceste instrumente preiau date preprocesate din mai multe surse și arată adevărurile revelate în forme grafice, ușor de înțeles.
Există sute de instrumente care se încadrează în această categorie. Vă place sau nu, cel mai utilizat este Microsoft Excel și instrumentele sale de graficare. Diagramele Excel sunt accesibile oricui folosește Excel, dar au funcționalități limitate. Același lucru este valabil și pentru alte aplicații pentru foi de calcul, cum ar fi Google Sheets și Libre Office. Dar vorbim aici despre instrumente mai specifice, special adaptate pentru business intelligence (BI) și analiza datelor.
Power BI
Nu cu mult timp în urmă, Microsoft și-a lansat Power BI aplicație de vizualizare. Poate prelua date din diverse surse, cum ar fi fișiere text, baze de date, foi de calcul și multe servicii de date online, inclusiv Facebook și Twitter, și le poate folosi pentru a genera tablouri de bord pline cu diagrame, tabele, hărți și multe alte obiecte de vizualizare. Obiectele tabloului de bord sunt interactive, ceea ce înseamnă că puteți face clic pe o serie de date dintr-o diagramă pentru a o selecta și a o utiliza ca filtru pentru celelalte obiecte de pe tablă.
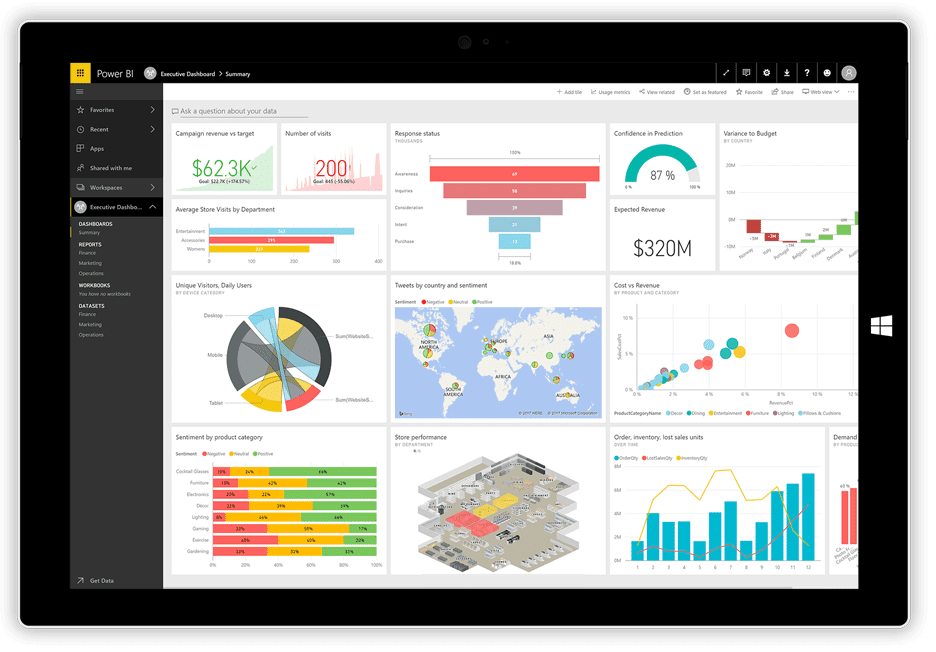
Power BI este o combinație între o aplicație desktop Windows (parte a suitei Office 365), o aplicație web și un serviciu online pentru a publica tablourile de bord pe web și a le partaja utilizatorilor. Serviciul vă permite să creați și să gestionați permisiuni pentru a acorda acces la panouri numai anumitor persoane.
Tablou
Tablou este o altă opțiune de a crea tablouri de bord interactive dintr-o combinație de mai multe surse de date. De asemenea, oferă o versiune desktop, o versiune web și un serviciu online pentru a partaja tablourile de bord pe care le creați. Funcționează în mod natural „cu felul în care gândești” (așa cum susține) și este ușor de utilizat pentru persoanele netehnice, ceea ce este îmbunătățit prin multe tutoriale și videoclipuri online.
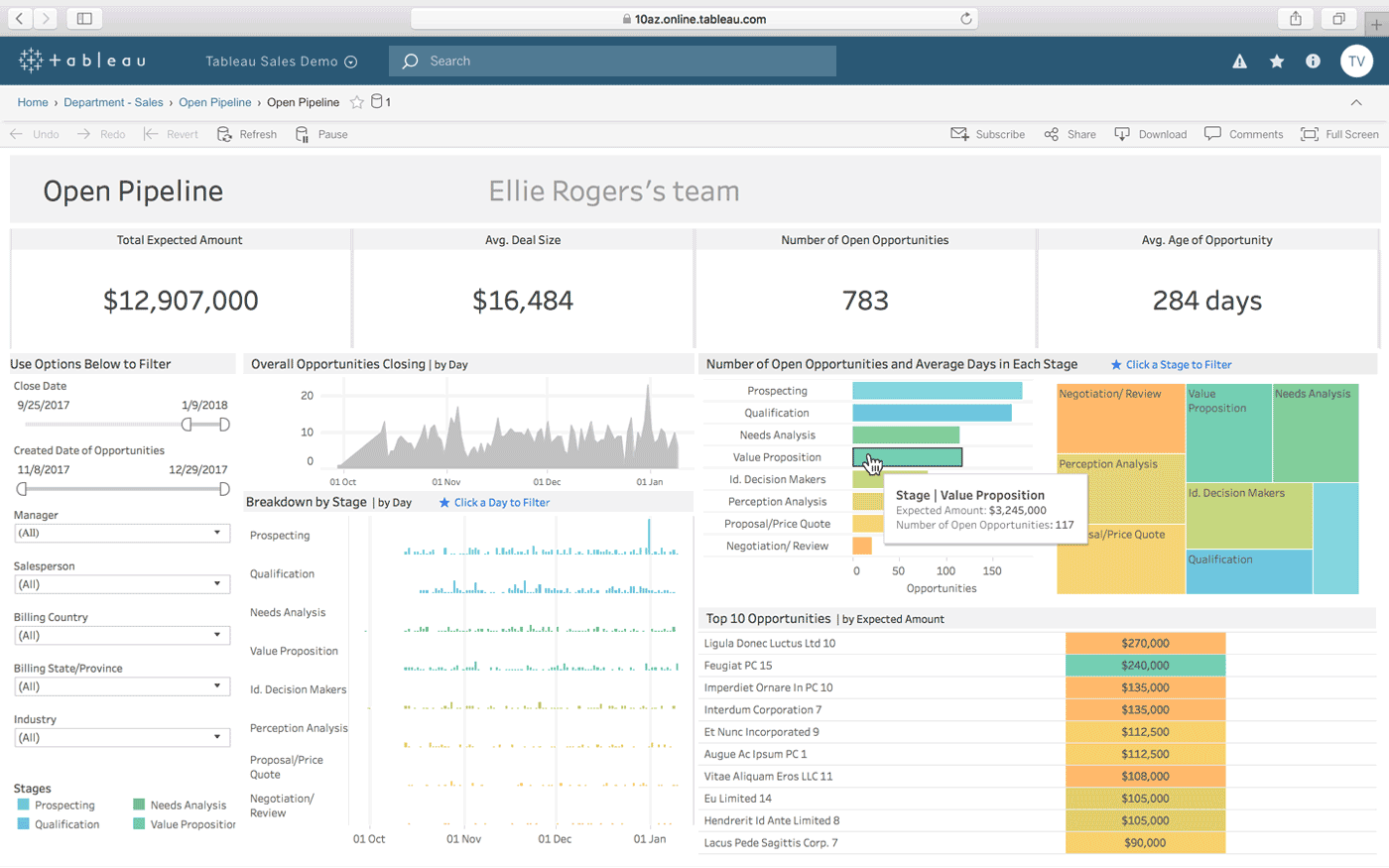
Unele dintre cele mai remarcabile caracteristici ale Tableau sunt conectorii de date nelimitați, datele live și în memorie și design-urile optimizate pentru mobil.
QlikView
QlikView oferă o interfață de utilizator curată și simplă pentru a ajuta analiștii să descopere noi perspective din datele existente prin elemente vizuale care sunt ușor de înțeles pentru toată lumea.
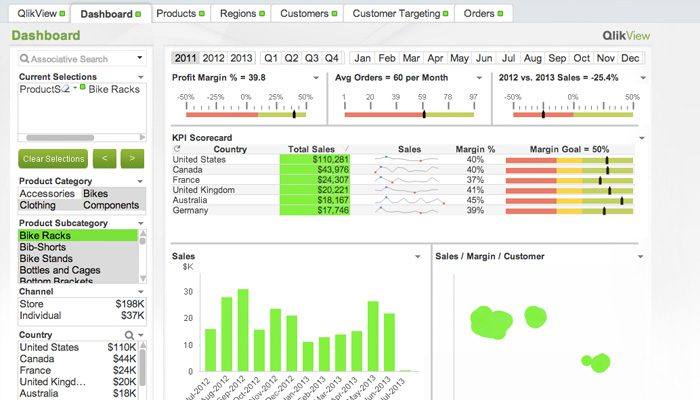
Acest instrument este cunoscut pentru că este una dintre cele mai flexibile platforme de business intelligence. Acesta oferă o caracteristică numită Căutare asociativă, care vă ajută să vă concentrați asupra celor mai importante date, economisind timpul necesar pentru a le găsi pe cont propriu.
Cu QlikView, puteți colabora cu partenerii în timp real, făcând analize comparative. Toate datele pertinente pot fi combinate într-o singură aplicație, cu funcții de securitate care restricționează accesul la date.
Instrumente de răzuit
În vremurile în care internetul tocmai a apărut, crawlerele web au început să călătorească împreună cu rețelele, adunând informații în calea lor. Pe măsură ce tehnologia a evoluat, termenul de web crawling s-a schimbat pentru web scraping, dar tot înseamnă același lucru: pentru a extrage automat informații de pe site-uri web. Pentru a face web scraping, utilizați procese automate, sau boți, care sar de la o pagină web la alta, extragând date din ele și exportându-le în diferite formate sau inserându-le în baze de date pentru analize ulterioare.
Mai jos rezumăm caracteristicile a trei dintre cele mai populare răzuitoare web disponibile astăzi.
Octoparse
Octoparse web scraper oferă câteva caracteristici interesante, inclusiv instrumente încorporate pentru a obține informații de pe site-uri web, care nu facilitează ca roboții de scraping să-și facă treaba. Este o aplicație desktop care nu necesită codificare, cu o interfață de utilizator ușor de utilizat, care permite vizualizarea procesului de extracție printr-un designer grafic de flux de lucru.
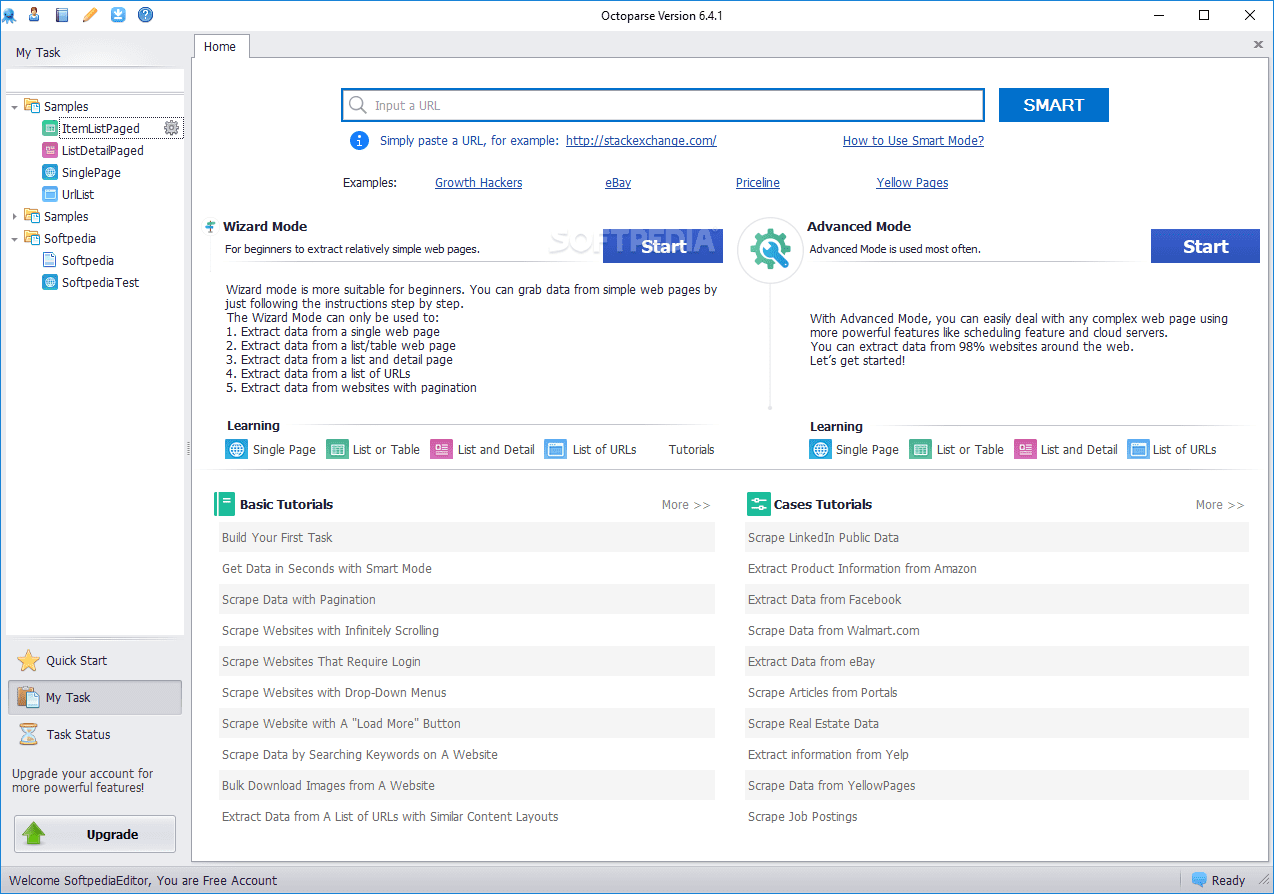
Împreună cu aplicația autonomă, Octoparse oferă un serviciu bazat pe cloud pentru a accelera procesul de extragere a datelor. Utilizatorii pot experimenta o creștere a vitezei de 4x până la 10x atunci când folosesc serviciul cloud în locul aplicației desktop. Dacă rămâneți la versiunea desktop, puteți utiliza Octoparse gratuit. Dar dacă preferați să utilizați serviciul cloud, va trebui să alegeți unul dintre planurile sale plătite.
Grabber de conținut
Dacă sunteți în căutarea unui instrument de răzuire bogat în funcții, ar trebui să puneți un ochi Grabber de conținut. Spre deosebire de Octoparse, pentru a utiliza Content Grabber, este necesar să aveți abilități avansate de programare. În schimb, obțineți editare de scripturi, interfețe de depanare și alte funcționalități avansate. Cu Content Grabber, puteți folosi limbaje .Net pentru a scrie expresii regulate. În acest fel, nu trebuie să generați expresiile folosind un instrument încorporat.
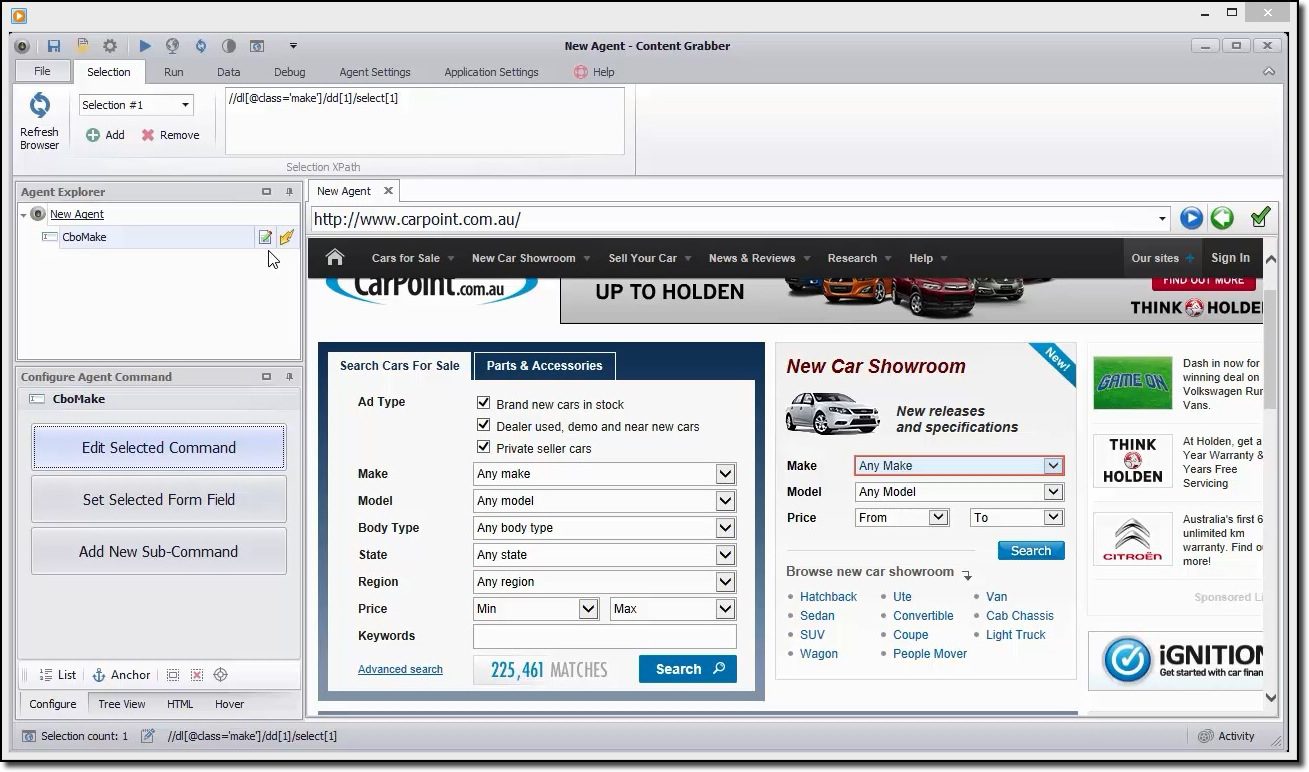
Instrumentul oferă o interfață API (Application Programming Interface) pe care o puteți utiliza pentru a adăuga capabilități de scraping la desktop și aplicațiile dvs. web. Pentru a utiliza acest API, dezvoltatorii trebuie să obțină acces la serviciul Windows Content Grabber.
ParseHub
Acest răzuitor poate gestiona o listă extinsă de diferite tipuri de conținut, inclusiv forumuri, comentarii imbricate, calendare și hărți. Se poate ocupa și de pagini care conțin autentificare, Javascript, Ajax și multe altele. ParseHub poate fi folosit ca o aplicație web sau o aplicație desktop capabilă să ruleze pe Windows, macOS X și Linux.
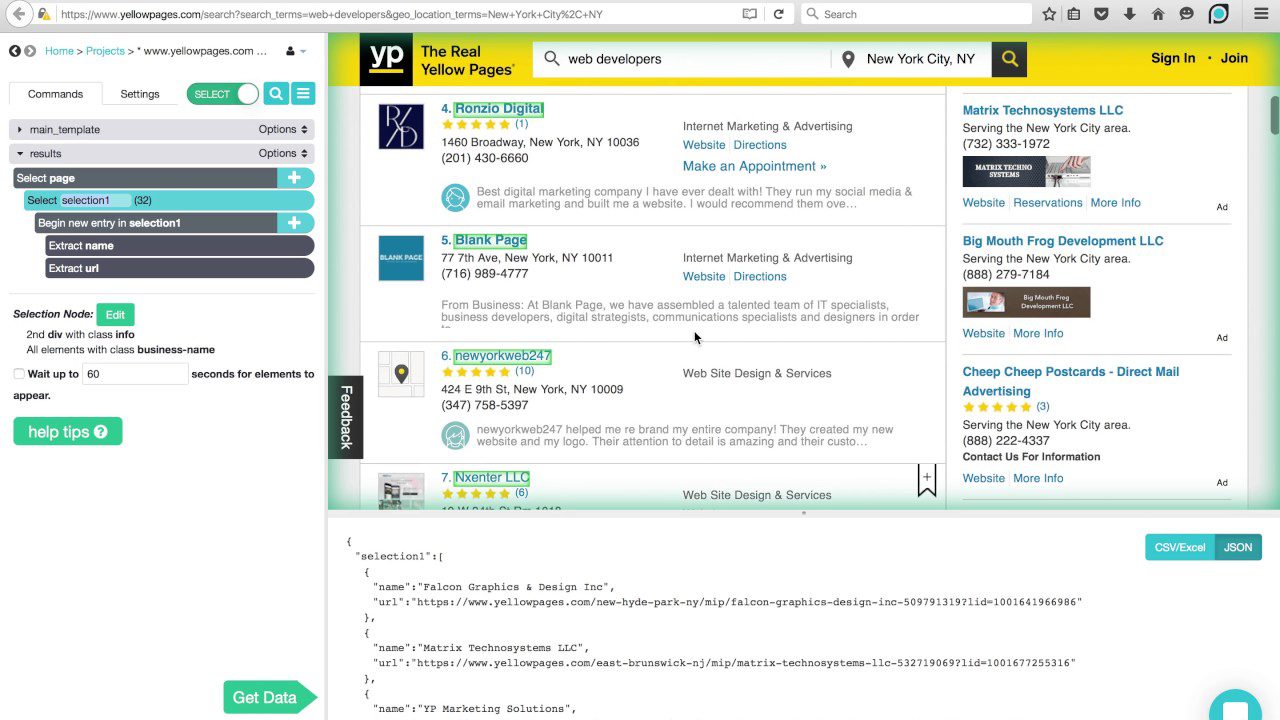
La fel ca Content Grabber, este recomandat să aveți cunoștințe de programare pentru a profita la maximum de ParseHub. Are o versiune gratuită, limitată la 5 proiecte și 200 de pagini per rulare.
Limbaje de programare
La fel cum limbajul SQL menționat anterior este conceput special pentru a funcționa cu baze de date relaționale, există și alte limbaje create cu un accent clar pe știința datelor. Aceste limbaje permit dezvoltatorilor să scrie programe care se ocupă de analiza masivă a datelor, cum ar fi statisticile și învățarea automată.
SQL este, de asemenea, considerată o abilitate importantă pe care dezvoltatorii ar trebui să o aibă pentru a face știința datelor, dar asta pentru că majoritatea organizațiilor au încă o mulțime de date despre bazele de date relaționale. Limbajele „adevărate” ale științei datelor sunt R și Python.
Piton

Piton este un limbaj de programare de nivel înalt, interpretat, de uz general, potrivit pentru dezvoltarea rapidă a aplicațiilor. Are o sintaxă simplă și ușor de învățat, care permite o curbă de învățare abruptă și reduceri ale costurilor de întreținere a programului. Există multe motive pentru care este limbajul preferat pentru știința datelor. Ca să menționăm câteva: potențialul de scripting, verbozitatea, portabilitatea și performanța.
Acest limbaj este un bun punct de plecare pentru oamenii de știință de date care intenționează să experimenteze mult înainte de a se lansa în munca reală și grea de prelucrare a datelor și care doresc să dezvolte aplicații complete.
R
The limbajul R este utilizat în principal pentru prelucrarea datelor statistice și reprezentarea grafică. Deși nu este menit să dezvolte aplicații cu drepturi depline, așa cum ar fi cazul pentru Python, R a devenit foarte popular în ultimii ani datorită potențialului său de data mining și de analiză a datelor.

Datorită unei biblioteci în continuă creștere de pachete disponibile gratuit, care își extind funcționalitatea, R este capabil să facă tot felul de lucrări de prelucrare a datelor, inclusiv modelare liniară/neliniară, clasificare, teste statistice etc.
Nu este o limbă ușor de învățat, dar odată ce vă familiarizați cu filosofia sa, veți face calcul statistic ca un profesionist.
IDE-uri
Dacă vă gândiți serios să vă dedicați științei datelor, atunci va trebui să alegeți cu atenție un mediu de dezvoltare integrat (IDE) care se potrivește nevoilor dvs., deoarece dvs. și IDE-ul dvs. veți petrece mult timp lucrând împreună.
Un IDE ideal ar trebui să reunească toate instrumentele de care aveți nevoie în munca de zi cu zi ca programator: un editor de text cu evidențiere de sintaxă și completare automată, un depanator puternic, un browser de obiecte și acces ușor la instrumente externe. În plus, trebuie să fie compatibil cu limba preferată, așa că este o idee bună să-ți alegi IDE-ul după ce știi ce limbă vei folosi.
Spyder
Acest IDE generic este destinat în mare parte oamenilor de știință și analiștilor care, de asemenea, trebuie să codifice. Pentru a le face confortabile, nu se limitează la funcționalitatea IDE – oferă, de asemenea, instrumente pentru explorarea/vizualizarea datelor și execuția interactivă, așa cum se poate găsi pe un pachet științific. Editorul din Spyder acceptă mai multe limbi și adaugă un browser de clasă, divizarea ferestrelor, trecerea la definire, completarea automată a codului și chiar un instrument de analiză a codului.
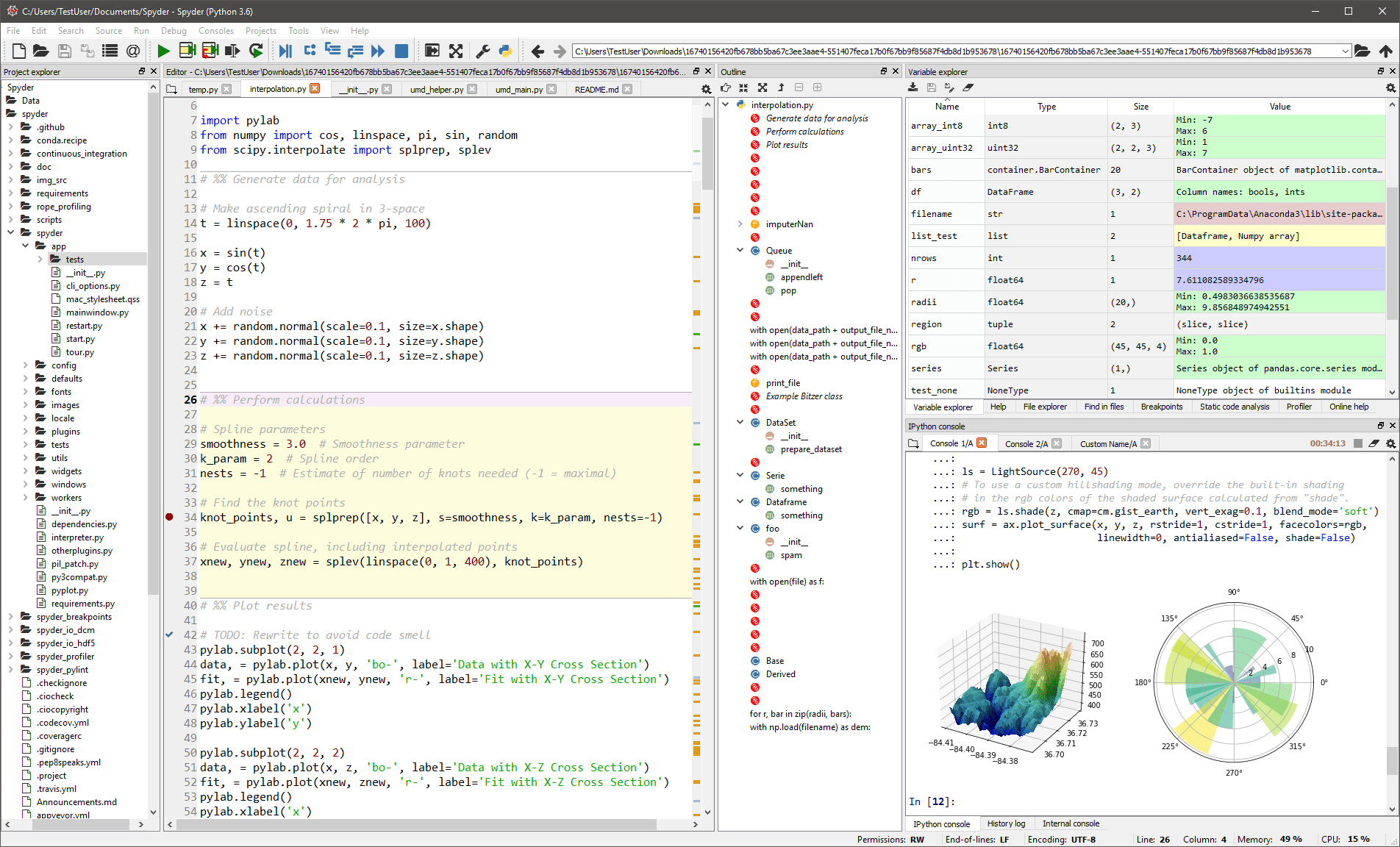
Depanatorul vă ajută să urmăriți fiecare linie de cod în mod interactiv, iar un profiler vă ajută să găsiți și să eliminați ineficiența.
PyCharm
Dacă programați în Python, sunt șanse ca IDE-ul ales să fie PyCharm. Are un editor de cod inteligent cu căutare inteligentă, completare a codului și detectarea și remedierea erorilor. Cu un singur clic, puteți sări din editorul de cod la orice fereastră legată de context, inclusiv test, supermetodă, implementare, declarație și multe altele. PyCharm acceptă Anaconda și multe pachete științifice, cum ar fi NumPy și Matplotlib, pentru a numi doar două dintre ele.
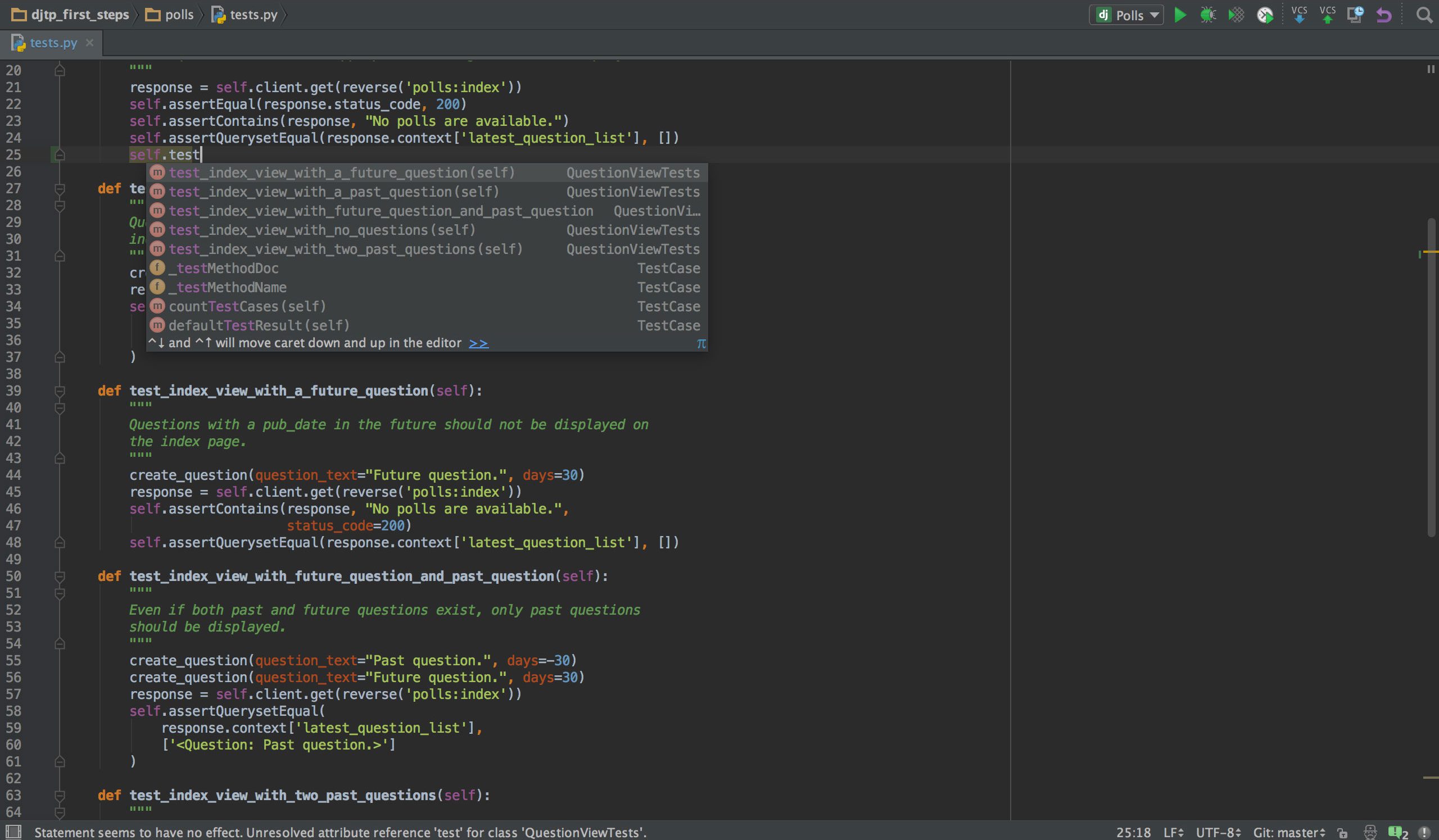
Oferă integrare cu cele mai importante sisteme de control al versiunilor și, de asemenea, cu un test runner, un profiler și un debugger. Pentru a încheia afacerea, se integrează și cu Docker și Vagrant pentru a asigura dezvoltarea și containerizarea pe mai multe platforme.
RStudio
Pentru acei oameni de știință de date care preferă echipa R, IDE-ul de alegere ar trebui să fie RStudio, datorită numeroaselor sale caracteristici. Îl puteți instala pe un desktop cu Windows, macOS sau Linux sau îl puteți rula dintr-un browser web dacă nu doriți să îl instalați local. Ambele versiuni oferă bunătăți, cum ar fi evidențierea sintaxelor, indentarea inteligentă și completarea codului. Există un vizualizator de date integrat care este util atunci când trebuie să răsfoiți datele tabulare.
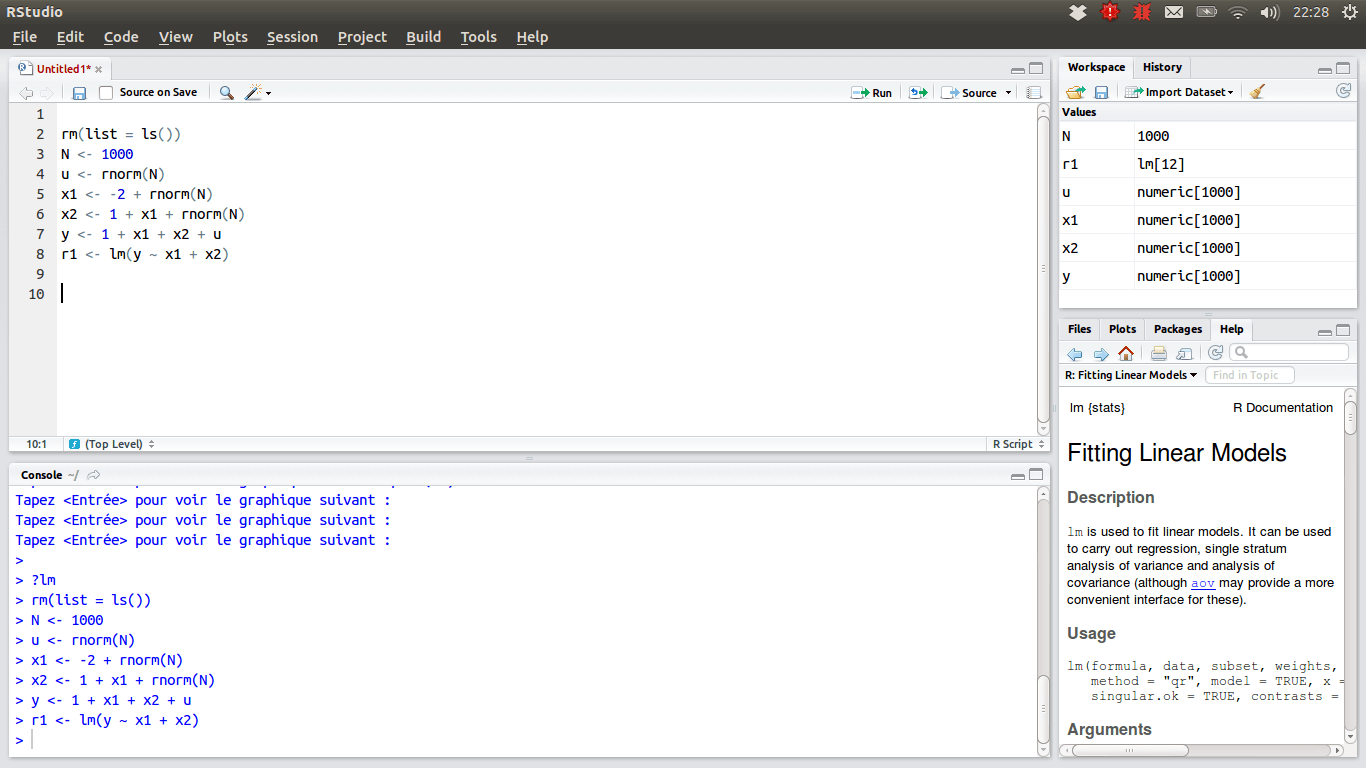
Modul de depanare permite vizualizarea modului în care datele sunt actualizate dinamic atunci când se execută un program sau un script pas cu pas. Pentru controlul versiunilor, RStudio integrează suport pentru SVN și Git. Un plus frumos este posibilitatea de a crea grafică interactivă, cu Shiny și oferă biblioteci.
Cutia ta de instrumente personală
În acest moment, ar trebui să aveți o vedere completă a instrumentelor pe care ar trebui să le cunoașteți pentru a excela în știința datelor. De asemenea, sperăm că v-am oferit suficiente informații pentru a decide care este cea mai convenabilă opțiune din fiecare categorie de instrumente. Acum depinde de tine. Știința datelor este un domeniu înfloritor dezvolta o cariera. Dar dacă vrei să faci asta, trebuie să ții pasul cu schimbările de tendințe și tehnologii, deoarece acestea apar aproape zilnic.